一般公開「高橋真人のプログラミング指南」
(MOSADeN Onlineでは、掲載日から180日を経過した記事を一般公開しています。)- 第222回 ファイルの扱いについて(6) 〜ランダムアクセス〜(2014/03/27:掲載)
- 第221回 ファイルの扱いについて(5) 〜Objective-Cでのケース・3〜(2014/01/31:掲載)
- 第220回 ファイルの扱いについて(4)〜Objective-Cでのケース・2〜(2013/11/29:掲載)
- 第219回 ファイルの扱いについて(3) 〜Objective-Cでのケース・1〜(2013/09/25:掲載)
- 第218回 ファイルの扱いについて(2)(2013/07/25:掲載)
- 第217回 ファイルの扱いについて(1)(2013/05/31:掲載)
- 第216回 関数と配列とポインタの関係〔後編〕 〜配列・構造体・ポインタ〜(2013/03/26:掲載)
- 第215回 関数と配列とポインタの関係〔前編〕 〜ポインタは、なぜ難しいのか?〜(2013/01/31:掲載)
- 第214回 Objective-Cから始めるプログラミング(11) 〜Objective-CにCの知識は不要?・1〜(2012/11/30:掲載)
- 第213回 Objective-Cから始めるプログラミング(10) 〜型について・6〜 クラス・3(2012/09/29:掲載)
- 第212回 Objective-Cから始めるプログラミング(9) 〜型について・5〜 クラス・2(2012/08/31:掲載)
- 第211回 Objective-Cから始めるプログラミング(8) 〜型について・4〜 クラス(2012/05/31:掲載)
- 第210回 Objective-Cから始めるプログラミング(7) 〜型について・3〜(2012/04/30:掲載)
- 第209回 Objective-Cから始めるプログラミング(6) 〜型について・2〜(2012/04/23:掲載)
- 第208回 Objective-Cから始めるプログラミング(5) 〜型について・1〜(2012/03/30:掲載)
- 第207回 Objective-Cから始めるプログラミング(4) 〜Hello world解説・2<関数>〜(2012/03/13:掲載)
- 第206回 Objective-Cから始めるプログラミング(3) 〜Hello world解説・1<関数>〜(2012/02/23:掲載)
- 第205回 Objective-Cから始めるプログラミング(2) 〜プロジェクトの始め方〜(2012/02/07:掲載)
- 第204回 Objective-Cから始めるプログラミング(1) 〜準備〜(2012/01/24:掲載)
- 第203回 Objective-Cから始めるプログラミング(0) 〜前口上〜(2012/01/17:掲載)
- 第202回 改めてCに挑戦!(21) 〜配列・7〜【文字列と配列について】(2011/12/28:掲載)
- 第201回 改めてCに挑戦!(20) 〜配列・6〜(2011/12/20:掲載)
- 第200回 改めてCに挑戦!(19) 〜配列・5〜(2011/11/30:掲載)
- 第199回 改めてCに挑戦!(18) 〜配列・4〜(2011/10/31:掲載)
- 第198回 改めてCに挑戦!(17) 〜配列・3〜(2011/10/22:掲載)
- 第197回 改めてCに挑戦!(16) 〜構造体・2〜(2011/09/30:掲載)
- 第196回 改めてCに挑戦!(15) 〜構造体・1〜(2011/09/27:掲載)
- 第195回 改めてCに挑戦!(14) 〜配列・2〜(2011/08/31:掲載)
- 第194回 改めてCに挑戦!(13) 〜配列・1〜(2011/08/25:掲載)
- 第193回 改めてCに挑戦!(12) 〜関数・8〜(2011/07/29:掲載)
-
第222回 ファイルの扱いについて(6) 〜ランダムアクセス〜
この記事は、2014年03月27日に掲載されました。前回まで、OS Xにおけるファイルの扱いについてANSI Cでのやり方とObjective-Cでのやり方を一通り見てきました。
原則として、ファイルのデータの読み書きはすべてシーケンシャル、つまり先頭から順に読んでいく/書き出していくというやり方で行いました。ですがファイルの読み書きには「シーケンシャルでないやり方」も存在します。
ファイルでのデータアクセスには、ファイル位置指示子(正式な名称は知りませんがここでは便宜上このように呼びます)という「現在のファイルの中の位置」を示すマーカーのようなものがあり、シーケンシャルに読み書きする場合は、このファイル位置指示子の位置からデータを読み書きすることになっています。また、この読み書きによって、読み書きしたデータの大きさの分だけファイル位置指示子が「先に」進みます。
つまり、ファイルが開いた時点でファイルの先頭に位置するファイル位置指示子は、データの読み書きにより順次先に進んで行くという形になるわけです。そこでランダムアクセス、つまり任意の場所のデータを読み出したり、任意の場所にデータを書き込んだりするためには、このファイル位置指示子の位置を自分で動かすことになります。
では最初に簡単な例。まずはシーケンシャルに文字列を書き出してみます。
01: #include <stdio.h> 02: #include <stdlib.h> 03: 04: int main(void) 05: { 06: char path[FILENAME_MAX]; 07: snprintf(path, sizeof(path), "%s/Desktop/random_test.txt", getenv("HOME")); 08: 09: FILE *fp = fopen(path, "wb"); 10: if (fp == NULL) { 11: fprintf(stderr, "Failed.\n"); 12: exit(1); 13: } 14: 15: fputs("apple\n", fp); 16: fputs("orange\n", fp); 17: fputs("pineapple\n", fp); 18: fputs("grape\n", fp); 19: 20: fclose(fp); 21: 22: printf("Done.\n"); 23: 24: return 0; 25: }ファイルを新たに作成し、文字列を4つ書き出しています。
走らせると、デスクトップに「random_test.txt」という名のテキストファイルが出来上がり、中身は、
apple orange pineapple grapeという感じになっているのが確認できると思います。
では、今度は文字列書き出すごとにファイル位置指示子を動かしてみます。ファイル位置指示子を動かすためにはfseek()という関数を使います。fseek()は、引数を3つ取る関数で、第1引数がファイルポインタ、第2引数が移動量、そして最後の引数は移動の際の基準点をどこにするかで、SEEK_CUR(現在位置)、SEEK_SET(ファイルの先頭)、SEEK_END(ファイルの末尾)の3通りの値を取ることができます。
では、文字列を書き出すごとに、ファイル位置指示子をさらに5バイト分進める例をお見せします。
01: #include <stdio.h> 02: #include <stdlib.h> 03: 04: int main(void) 05: { 06: char path[FILENAME_MAX]; 07: snprintf(path, sizeof(path), "%s/Desktop/random_test.txt", getenv("HOME")); 08: 09: FILE *fp = fopen(path, "wb"); 10: if (fp == NULL) { 11: fprintf(stderr, "Failed.\n"); 12: exit(1); 13: } 14: 15: fputs("apple\n", fp); 16: fseek(fp, 5L, SEEK_CUR); 17: fputs("orange\n", fp); 18: fseek(fp, 5L, SEEK_CUR); 19: fputs("pineapple\n", fp); 20: fseek(fp, 5L, SEEK_CUR); 21: fputs("grape\n", fp); 22: fseek(fp, 5L, SEEK_CUR); 23: 24: fclose(fp); 25: 26: printf("Done.\n"); 27: 28: return 0; 29: }新規に作成された(前にあったファイルは上書きされる)random_test.txtの中身は、以下のようになります。
apple ^@^@^@^@^@orange ^@^@^@^@^@pineapple ^@^@^@^@^@grapeこの「^@」という文字ですが、これはたまたま私が使ったエディタがこのように表記しているだけで、実際は「ヌル文字」です。つまり、fseek()によって余分に先に進められたところにはデータが書き込まれなかったので、結果としてヌル文字で埋められています。ただし、必ずヌル文字であるかどうかの保証はないようです。(処理系依存)
あと、grapeを書き出した後にも5バイト分動かしていますが(22行目)、このfseek()は利いていません。これは、単にファイル位置指示子を移動しただけではファイルのサイズが変わらず、実際にデータを書き込んだ時点で初めてファイルのサイズが拡張されるということを意味しています。
fseek()はファイル位置指示子を移動させる関数ですが、これに対してftell()という関数があり、こちらは現在のファイル位置指示子の位置を返します。この位置は、先頭から何バイト離れているかということを表しますので、例えば以下のようにすると任意のファイルのサイズを調べることができます。
01: #include <stdio.h> 02: #include <stdlib.h> 03: 04: long get_file_size(FILE *fp); // ファイルのサイズを得る 05: 06: int main(void) 07: { 08: char path[FILENAME_MAX]; 09: snprintf(path, sizeof(path), "%s/Desktop/random_test.txt", getenv("HOME")); 10: 11: FILE *fp = fopen(path, "rb"); 12: if (fp == NULL) { 13: fprintf(stderr, "Failed.\n"); 14: exit(1); 15: } 16: 17: long file_size = get_file_size(fp); 18: 19: fclose(fp); 20: 21: printf("Length: %ld.\n", file_size); 22: 23: return 0; 24: } 25: 26: long get_file_size(FILE *fp) 27: { 28: long cur_pos = ftell(fp); // 現在の位置を保存しておく 29: fseek(fp, 0L, SEEK_END); // ファイル位置指示子を末尾に移動 30: long file_size = ftell(fp); 31: 32: fseek(fp, cur_pos, SEEK_SET); // ファイル位置指示子を元に戻す 33: 34: return file_size; 35: }ところで、ファイル位置指示子を先頭に戻すには、
fseek(fp, 0L, SEEK_SET);とすればいいのですが、これと同じ働きをする専用の関数も用意されています。
rewind(fp);リワインド、つまり「巻き戻し」ってことです。分かりやすいですね。
では、今度はこのrewind()を使ってファイル位置指示子を「戻す」例をお見せしましょう。
01: #include <stdio.h> 02: #include <stdlib.h> 03: 04: int main(void) 05: { 06: char path[FILENAME_MAX]; 07: snprintf(path, sizeof(path), "%s/Desktop/random_test.txt", getenv("HOME")); 08: 09: FILE *fp = fopen(path, "wb"); 10: if (fp == NULL) { 11: fprintf(stderr, "Failed.\n"); 12: exit(1); 13: } 14: 15: fputs("apple\n", fp); 16: rewind(fp); 17: fputs("orange\n", fp); 18: rewind(fp); 19: fputs("pineapple\n", fp); 20: rewind(fp); 21: fputs("grape\n", fp); 22: 23: fclose(fp); 24: 25: printf("Done.\n"); 26: 27: return 0; 28: }コードを見れば何をやっているのかは分かると思いますが、文字列を書き出す度にファイル位置指示子をファイルの先頭に戻して、再度文字列を書き出す、ということを繰り返しています。
結果は、以下のようになりました。
grape ple二行目に「ple」というのがありますが、これは「pineapple」と書き込んだところに最後の「grape」(と改行)が上書きされたため、残りの部分が表示されているわけです。
さて、何となくランダムアクセスのイメージがつかめたでしょうか? では、Foundationフレームワークにはランダムアクセスの仕組みはあるのかというと、実はあります。以前にも紹介したNSFileHandleというクラスで可能です。このクラスには、
- (unsigned long long)offsetInFile - (unsigned long long)seekToEndOfFile - (void)seekToFileOffset:(unsigned long long)offsetという3つのメソッドがあり、これらで先ほど紹介したのとほぼ同様のことができます。ただし、こちらは移動量を表す型がunsigned long longとなっています。実は、昨今のファイルサイズの巨大化により、場合によってはlongだけではファイルサイズを表すには足りないケースもあったりしますので、Foundationではunsigned long longという型を使っています。
実は、ANSI Cにも大きなファイルに対応する関数はありまして、fgetpos()とfsetpos()という関数がそれに当たります。これらではfpos_tという型が定義されていて、これの実体はlong longです。
さて、ランダムアクセスについて簡単に見てきましたが、実はランダムアクセスは今の時代に必要になることはあまりないのではないか、というのが私の印象です。私が今までコードを書いてきた中で、ランダムアクセスが必要になったことはほとんどありません。
理由は、2つ。
1つは、ファイルのデータ全量をNSDataに読み込んでしまい、そのNSDataの中から必要なデータを取り出せば足りたということ。
もう1つは、ランダムアクセスが必要になるケースでは、ほとんどが構造体などをそのまま書き込む形になるわけですが、構造体は環境が変わると互換性が失われるので取り扱いが面倒だからです。(バイトオーダーやパディング、アライメントなどの関係です)
もっとも、私の場合、扱うデータはテキスト系のものが圧倒的に多く、特にムービーやサウンドを扱ったりすることはまずないので。万が一、これらを扱うことになっても、上記のようにメモリ上に読み込んで扱うか、あとはOSが提供する機能か既存のライブラリを利用するでしょうから、自分でファイル位置指示子を動かすようなコードを書くことはまずないと言えます。
参考までに触れておきますと、UNIX系のOSにはmmap()なる関数(ANSI Cライブラリにはない)があり、これを使うとファイルの中身を仮想メモリ上にマッピングして扱うことができます。もちろんOS Xでも使用できますが、私自身は必要になったことがありません。
OS X上で動作するプログラムの場合、最近はCore Dataを使って処理することがほとんどです。Core Dataならかなり膨大な量のデータも容易に扱えます。
また、他の環境とのやり取りが発生するようなケースでは、XMLを利用することが多いです。先ほど触れたように、(構造体を読み書きする)バイナリデータは環境ごとの互換性の面で難があるので、既に規格化されているデータを扱うとか、何らかの事情でバイナリを使うしかないような場合を除き、バイナリデータを使うのは汎用性の面であまりお勧めできません。
これに対して、プレーンテキストのファイルは汎用性の面で優れているので、構造的なデータをテキストとして扱うことのできるXMLは無難に使うことができるのではないかと思います。
ちなみに、OS X/iOSに限る場合は、プロパティリストという形式を使うのもありかもしれません(OSがサポートしてくれるので比較的簡単に扱える)。OS Xの初期設定ファイルなどではこのplist形式は多く用いられていますね。あ、あと今どきのWeb系の場合には、JSONなんてのもありかもしれません。
-
第221回 ファイルの扱いについて(5) 〜Objective-Cでのケース・3〜
この記事は、2014年01月31日に掲載されました。前回に予告しました「NSStreamを使用してファイルから非同期に読み取る」例について、今回はコードを実際にご紹介しながら解説します。
同じデータファイルに対して、同期で読み込むやり方と非同期で読み込むやり方を紹介して、実際に皆さんご自身の環境で走らせて実験してみれるようにしたいと思います。
まず、同期のやり方のご紹介ですが、その前に、今回のサンプルで読み込みの対象となるデータを作成するプログラムです。まあ、本来は既存のデータを処理するのがいいのでしょうが、説明をしやすくするために今回は特定のファイルを対象とすることにします。
で、サンプルデータもプログラムから生成してしまうことにしましょう。ここは少し遊んで、C++のコードとして書いてみました。C++に馴染みのない方も多いでしょうが、Xcodeで普通に動作しますので試しにやってみてください。
以下、Xcode 5での手順を説明します。
基本的にはiOSのアプリを作るのと同じですが、少し違う部分もあります。- 新規にプロジェクトを作成する(メニューから)
- 新規プロジェクトのダイアログで、左側で「OS X」を選び、右側で「Command Line Tool」を選んで「Next」
- 名前は適当にどうぞ。残りの部分もいつもやってる感じと同じでいいです。ただ、「Type」のポップアップメニューは「C++」を選んでください
- 適当な場所に保存すれば完了です
- ファイルリストの部分に「main.cpp」というファイルがありますが、これがソースコードを記述するところです
- コードは以下のものを入力してください(もちろん、先頭の行番号は除いて)
01: #include <fstream> 02: #include <string> 03: #include <random> 04: 05: int main() 06: { 07: const int NUM_OF_TWEETS = 10000000; 08: 09: std::string filepath(getenv("HOME")); 10: filepath.append("/Desktop/random_tweets.txt"); 11: 12: std::ofstream ofs(filepath.c_str()); 13: if (ofs) { 14: std::string base("abcdefghijklmnopqrstuvwxyz0123456789"); 15: std::mt19937 engine; 16: std::uniform_int_distribution<int> distribution(5, 13); 17: 18: for (int i = 0; i < NUM_OF_TWEETS; ++i) { 19: std::random_shuffle(base.begin(), base.end()); 20: ofs << base.substr(0, distribution(engine)).c_str() 21: << "\tHello world! Good-bye world! See you later!\n"; 22: } 23: } 24: 25: return 0; 26: }ホントに遊んでいるので(笑)、C++の心得のある方でも見慣れないものがあるかもしれませんが、やっているのは以下のようなことです。
まず、ファイルのパスをデスクトップに設定して、次にTwitterのアカウントっぽい(?)文字列をランダムに生成し、それにタブ文字と適当なツイート文と改行コードを接続して1行にしたものをNUM_OF_TWEETS回分ファイルに書き込んでいるというわけです。
乱数生成の部分に、C++11という新しい規格で装備された乱数生成の仕組みを使っています。きょうのみある方は関連のサイトを調べていただきたいのですが、要は、最終的に欲しいのは、20行の部分です。
ランダムなTwitterアカウント(っぽいもの)を生成するために、
- アルファベットと数字からなるベースの文字列を生成。(14行目)
- ベース文字列をシャッフル。(19行目)
- ベース文字列の先頭から、5〜13文字の範囲で取り出し、アカウントとする。(20行目)
という具合です。ここの、「5〜13」というのを、16行目のコードが指定しているわけです。
さて、上記のコードを走らせるとデスクトップに「random_tweets.txt」という名のテキストファイルが出来上がるので、これを使って以下のプログラム用の「ダミーデータ」ということにするわけです。NUM_OF_TWEETSに10,000,000というかなり大きな数を設定しているのでプログラムが完了するのにある程度時間がかかるかもしれません。
これは、後で紹介するプログラムで、同期と非同期の違いが分かるためには、このぐらいのデータサイズ(私が試した結果は540MB)がないと分かりにくいのです。
まあ、逆に言えば今のパソコンはちょっとやそっとのテキストファイルならば余裕で扱えるっていうことでもありますね。
では、いよいよ本題のプログラムです。
今回は、簡単なものながら、一応Cocoaのプログラムということになるので、図を交えて説明をしていきます。まずは、Xcodeで新しいプロジェクトを作成しますが、今度はOS Xの「Cocoa Application」を選びます。
Product Nameの所は適当でいいのですが、とりあえず「TweetsReader」としておきます。あとは、図を見ながら似たような感じに設定してください。Class Prefixというところは、ま、お好きなように。ここでは「TRD」としました。

あとは、先ほどと同じように保存場所を指定したら終わりです。
では、まず最初にインターフェースを作ります。
ファイルリストで「MainMenu.xib」を選びます。
レイアウト画面が表示されますので、左側の縦にアイコンが並んでいるところから、下から3つめのウインドウのアイコンを選択します。

右側の「Object Library」から、「Push Button」を選んで、ウインドウ上に2つ配置します。そして、それぞれに「Read Sync」、「Read Async」と名前を付けてください。大きさは適当に広げておきます。
ファイルリストからヘッダファイル(TRDAppDelegate.h)を選び、Navigateメニューから「Open in Assistant Editor」を選びます。すると、エディタがもう1つ開き、両方にヘッダが表示された状態になりますので、再度「MainMenu.xib」を選び直して、以下のようになるようにします。

左側のRead Syncボタンから、Controlキーを押した状態で、マウスをドラッグすると、青い線が延びますので、右側のヘッダファイルの末尾の@endとあるとこのすぐ上まで持っていって放します。

ポップアップが出ますので、Connectionとある右側のポップアップメニューを「Action」に切り替え、Nameの欄に「readSync」と入れてConnectポタンをクリックします。(ヘッダファイルにメソッドの宣言文が挿入されます)

同様に、Read Asyncボタンからも同じようにして、名前はreadAsyncとします。
以上が済んだ状態が以下です。

以上でインターフェースの準備はおしまいです。
ヘッダファイルに少し追加をします。
最終的に、以下のようになるようにしてください。
01: #import <Cocoa/Cocoa.h> 02: 03: @interface TRDAppDelegate : NSObject <NSApplicationDelegate, NSStreamDelegate> { 04: NSString *filePath; 05: NSMutableData *mutableData; 06: NSInputStream *inputStream; 07: NSUInteger tweetsCount; 08: } 09: 10: @property (assign) IBOutlet NSWindow *window; 11: 12: - (IBAction)readSync:(id)sender; 13: - (IBAction)readAsync:(id)sender; 14: 15: - (void)readTweets; 16: 17: @endあとは、実装コードを書いていくだけですので、アシスタントエディターを閉じて、改めて「TRDAppDelegate.m」を選択します。
先ほどのドラッグ操作でヘッダに挿入された部分に対応する実装部分の枠組みが作られているのが確認できると思います。この辺を利用しながら、最終的に、以下のようになるようにコードを打っていきます。
001: #import "TRDAppDelegate.h" 002: 003: @implementation TRDAppDelegate 004: 005: - (void)awakeFromNib 006: { 007: filePath = [NSHomeDirectory() stringByAppendingPathComponent:@"Desktop/random_tweets.txt"]; 008: } 009: - (void)applicationDidFinishLaunching:(NSNotification *)aNotification 010: { 011: // Insert code here to initialize your application 012: } 013: 014: - (IBAction)readSync:(id)sender 015: { 016: tweetsCount = 0; 017: mutableData = [[NSMutableData alloc] initWithContentsOfFile:filePath]; 018: [self readTweets]; 019: } 020: 021: - (IBAction)readAsync:(id)sender { 022: tweetsCount = 0; 023: mutableData = [[NSMutableData alloc] init]; 024: 025: inputStream = [[NSInputStream alloc] initWithFileAtPath:filePath]; 026: [inputStream setDelegate:self]; 027: [inputStream scheduleInRunLoop:[NSRunLoop currentRunLoop] forMode:NSRunLoopCommonModes]; 028: [inputStream open]; 029: } 030: 031: - (void)readTweets 032: { 033: uint8_t *top = (uint8_t *)[mutableData bytes]; 034: NSUInteger limit = [mutableData length]; 035: 036: uint8_t *lfPos = memchr(top, '\n', limit); 037: uint8_t *tabPos = memchr(top, '\t', limit); 038: 039: if (tabPos == NULL) { 040: return; 041: } 042: 043: if (lfPos == NULL || tabPos < lfPos) { 044: lfPos = top; 045: } 046: 047: while (YES) { 048: NSRange range = NSMakeRange(lfPos - top + 1, tabPos - lfPos - 1); 049: if (limit <= range.location + range.length) { 050: NSLog(@"Out of Bounds!"); 051: break; 052: } 053: 054: NSString *account = [[NSString alloc] initWithData:[mutableData subdataWithRange:range] encoding:NSASCIIStringEncoding]; 055: // printf("%s\n", [account UTF8String]); 056: if ([account length]) { 057: ++tweetsCount; 058: 059: if (tweetsCount % 1000000 == 0) { 060: printf("%ld tweets read.\n", tweetsCount); 061: } 062: } 063: 064: 065: lfPos = memchr(tabPos, '\n', limit - (tabPos - top)); 066: if (lfPos == NULL) { 067: NSRange r = NSMakeRange(0, tabPos - top + 1); 068: [mutableData replaceBytesInRange:r withBytes:NULL length:0]; 069: break; 070: } 071: 072: tabPos = memchr(lfPos, '\t', limit - (lfPos - top)); 073: if (tabPos == NULL) { 074: NSRange r = NSMakeRange(0, lfPos - top + 1); 075: [mutableData replaceBytesInRange:r withBytes:NULL length:0]; 076: break; 077: } 078: } 079: 080: if (lfPos - top == limit - 1 || tabPos - top == limit - 1) { 081: mutableData = [[NSMutableData alloc] init]; 082: } 083: } 084: 085: - (void)stream:(NSStream *)aStream handleEvent:(NSStreamEvent)streamEvent 086: { 087: const NSUInteger bufLen = 32768; 088: uint8_t buffer[bufLen]; 089: NSUInteger actualRead; 090: 091: switch (streamEvent) { 092: case NSStreamEventNone: 093: break; 094: 095: case NSStreamEventOpenCompleted: 096: break; 097: 098: case NSStreamEventHasBytesAvailable: 099: actualRead = [(NSInputStream *)aStream read:buffer maxLength:bufLen]; 100: [mutableData appendBytes:buffer length:actualRead]; 101: [self readTweets]; 102: 103: case NSStreamEventHasSpaceAvailable: 104: break; 105: 106: case NSStreamEventErrorOccurred: { 107: printf("NSStreamEventErrorOccurred.\n"); 108: NSError *error = [aStream streamError]; 109: [[NSApplication sharedApplication] presentError:error]; 110: break; 111: } 112: 113: case NSStreamEventEndEncountered: 114: break; 115: } 116: } 117: 118: @end以上で完了です。
では、実際にアプリケーションを走らせてみましょう。
デスクトップ上に先ほどのアプリで作ったファイルがあれば、うまく動くはずです。最初にRead Syncのボタンを押してみましょう。Xcodeのデバッグエリアに1,000,000アカウントを読み込むごとにログが書き出されます。
次に、Read Asyncの方を試してみてください。両者での違いは分かりましたか?
これが同期と非同期の違いです。次回、もう少し細かく見て行きたいと思います。
-
第220回 ファイルの扱いについて(4)〜Objective-Cでのケース・2〜
この記事は、2013年11月29日に掲載されました。前々回、Cでのファイル読み込みについて言及した際に、「今の時代なら、数メガ程度のファイルをメモリに丸ごと読み込んで処理しても問題ない」と申しました。また、どっかで書いたと思いますが、Objective-CというかFoundationフレームワークの機能には、ファイルを行単位で処理するという仕組みはありません。
ただ、たまたま少し前に仕事で調べていて、実は「Foundationフレームワークにも行単位の処理を前提とした仕組みがあった」ことを知りました。これって、一瞬「前言を否定している」と思われるかもしれませんが、そうでもありません。よく比較してみると「微妙な違い」があります。それは「ファイルかどうか」です。
Foundationでは、NSStringという文字列を表すクラスにいくつかの「行の処理を意識した」メソッドが用意されています。以下がそれらになります。
- (void)getLineStart:(NSUInteger *)startIndex end:(NSUInteger *)lineEndIndex contentsEnd:(NSUInteger *)contentsEndIndex forRange:(NSRange)aRange - (NSRange)lineRangeForRange:(NSRange)aRange 【10.3以降】 - (void)getParagraphStart:(NSUInteger *)startIndex end:(NSUInteger *)endIndex contentsEnd:(NSUInteger *)contentsEndIndex forRange:(NSRange)aRange - (NSRange)paragraphRangeForRange:(NSRange)aRange 【10.6以降】 - (void)enumerateLinesUsingBlock:(void (^)(NSString *line, BOOL *stop))block現在のところ、全部で5つあります。最後の10.6以降でのみ使える -enumerateLinesUsingBlock: というのはおなじみの(とは言ってもこの連載では触れたことはありませんが)ブロック構文を使用するものです。今回は触れません。
で、先頭の2つと、10.3以降で使えるというそのあとの2つはほとんど同じで、違いは、前者が「Line」で後者が「Paragraph」となっているところです。つまり「行」と「段落」。
行と段落では何が違うのでしょう? 文章を編集するエディタとか、レイアウトされた文章などの場合は、行と段落には違いがありますが、ここではNSStringのオブジェクトの中に格納されているUnicodeテキストが対象となっていますので、いわゆる「折り返し」による行などは考慮外となります。
では、何が違うかというと、前者(Line)では「U+2028というUnicodeの行区切り文字として定義されたコード」が区切りとして使われるか否かという違いのみです。なので、それ以外の区切り記号である以下のもの
- U+000D: いわゆるCR
- U+000A: いわゆるLF
- CR+LF、つまりDOS/Windowsでの改行コード
- U+2029: Unicodeの段落区切り記号
は共通して区切りとして使われます。特に前3つをすべて区切りとみなしてくれるために、少なくとも環境に依存しない行区切り処理を行うには便利とは言えるかもしれません。要は、Windowsで作成されたテキストデータをMac上で編集したりする場合に、改行コードの違いをいちいち意識しなくて済むというメリットはあると思います。
それでも、これらはNSStringオブジェクトに対して機能するものですから、あくまでデータがメモリ上にあることを前提にしているということで、「ファイルから行単位で読み込んでくるものではない」ということです。
そんなわけで、これらの機能を使用して「ファイルを行単位で処理する」ことは残念ながらできませんが、せっかくなので使い方をちょっと見てみましょう。
01: #import <Foundation/Foundation.h> 02: 03: void doDemo(void); 04: 05: int main (int argc, const char * argv[]) { 06: NSAutoreleasePool * pool = [[NSAutoreleasePool alloc] init]; 07: 08: doDemo(); 09: 10: [pool drain]; 11: return 0; 12: } 13: 14: void doDemo(void) 15: { 16: NSString *string = @"Hello world!\rGood-bye, world...\n" 17: "こんにちは、世界!!\r\nこんにちは、日本。\n" 18: "Hey, what's up?\n\rSo long."; 19: 20: NSUInteger startIndex, lineEndIndex, contentsEndIndex; 21: NSRange r = NSMakeRange(0, 0); 22: NSInteger count = 0; 23: 24: while (r.location < [string length]) { 25: [string getLineStart:&startIndex 26: end:&lineEndIndex 27: contentsEnd:&contentsEndIndex 28: forRange:r]; 29: 30: NSString *s = [string substringWithRange: 31: NSMakeRange(startIndex, contentsEndIndex - startIndex)]; 32: 33: printf("paragraph[%d]: %s\n", count, [s UTF8String]); 34: 35: r.location = lineEndIndex; 36: ++count; 37: } 38: 39: printf("\nDemo done.\n"); 40: }走らせてみると、こんな感じになります。
paragraph[0]: Hello world! paragraph[1]: Good-bye, world... paragraph[2]: こんにちは、世界!! paragraph[3]: こんにちは、日本。 paragraph[4]: Hey, what's up? paragraph[5]: paragraph[6]: So long. Demo done.6行目(paragraph[5])のところに注目してください。ここが空白になっているのは、\n\r、つまりLF+CRと並んでいるのを「2つの改行」と見なしたからです。それに対して「こんにちは、世界!!」のあとはCR+LFなのでこれは「1つの改行」と見なしています。
このように、CRとLFとCR+LFが混在したテキストデータでもちゃんと行単位に分割してくれているのが分かると思います。
さて、ちょっと寄り道をしましたが、結局のところFoundationフレームワークにはファイルを行単位で読み込んできて処理をする仕組みはありません。前々回、「全部丸ごとメモリに読み込んで処理しても問題ない」と言いましたが、パフォーマンスの理由から、丸ごとメモリに読み込まずに、というか先頭から順に処理していきたいというニーズも時々はあります。
そもそも、ファイルからテキストデータを読み込んでNSStringのオブジェクトに格納する場合、データはUnicodeのUTF-16に変換されます。ですから、もともとファイル自体のエンコーディングがUTF-16でなければ、ASCIIやシフトJISやUTF-8をUTF-16に変換する処理が間に入ることになります。それと、ファイルのデータをすべてメモリに読み込んでから処理するのと、ファイルから読み込みつつ処理をするのでは、全体にかかる時間には大きな違いはないかもしれませんが、後者だと「すぐに処理が走り出す」感じになります。
どういうことかを例を挙げて説明します。
例えばTwitterのツイートをたくさん集めたデータがテキストファイルに保存されていて、ファイルサイズが数100MBあるとしましょう。ファイルの中のデータは、Twitter ID<タブ>ツイート内容 <改行> Twitter ID<タブ>ツイート内容 <改行> Twitter ID<タブ>ツイート内容 <改行> Twitter ID<タブ>ツイート内容 <改行> ...という形で、行ごとに「Twitter ID」とツイート内容がタブ(0×09)で区切られたものが格納されているとします。ところが、今回のプログラムで必要なのはあくまで最初のTwitter IDの部分であって、後ろのTweet部分は必要なかったとします。
こんな場合、ファイルの中に含まれるデータの中で必要とするのはほんの一部なのにも関わらず、ファイル全体を舐めなければならないわけです。もちろん、ファイル内のデータをまとめてメモリの中に読み込んでから必要な部分のみを切り出してくるという方法も当然ありですが、それだとたぶんファイルを読み込むところで少し待たされることになると思います。
こんな時に、ファイルを読み込みながらデータを逐次処理していくという方法が有効です。また、今回は触れませんが、ファイルが別のマシン上にありネットワークを通して読み込んでこなければならないような場合、特にこの方法は有効だと思います。
では、どんなふうにファイルからデータを読んでいくのでしょう?
NSDataやNSStringの用意しているメソッドは基本的にファイルのデータを丸ごと読み込んでしまうようになっています。これに対して、NSStreamやNSFileHandleというクラスを使うと、ファイルのデータを先頭から順次読み込んでいく処理を行うことが可能です。
NSStreamには、NSInputStreamとNSOutputStreamというサブクラスがあって、実際に読み書きにはそれらを使うのですが、主にこれらが使われるのはネットワーク経由でのデータの読み書きの方が多いと思います。ただ、Mac OS Xの基盤であるUNIXでは、外部のものをすべてファイルとして扱うようになっているため、ネットワークもファイルとして扱っているわけです。ですから、ネットワーク処理に使われることが多いNSStreamもファイルに対して使うことができるのです。
ファイルからデータを読み込む場合、NSInputStreamを使います。
NSInputStreamでは、ファイルの読み込みには以下のものを使います。- (NSInteger)read:(uint8_t *)buffer maxLength:(NSUInteger)lenこれは、CのANSI Cライブラリにおけるread()という関数とほぼ同様の使い方になります。
ssize_t read(int fildes, void *buf, size_t nbyte);NSInputStreamには
- (BOOL)getBuffer:(uint8_t **)buffer length:(NSUInteger *)lenというメソッドも用意されていて、リファレンスの説明を読むと「bufferの領域も自動的に確保してくれる」ようにも読めるのですが、実際に動かしてみるとうまく動かないみたいです。ざっと調べてみたところ、これはNSInputSreamのサブクラスでオーバーライドするために用意されている仕組みのように私には読めました。
ところで、NSInputStreamのread:maxLength:は、データを片っ端から読み込んで処理していくようなシンプルなツール的なプログラムを書く場合にはよいのですが、GUIを伴うアプリケーションで使うと、この部分が制御を独占してしまうため、ファイルの最後まで読み終わらないとユーザーに制御が戻りません。これは扱うファイルが大きい時には、ずっとレインボーカーソルが回ったまま、ということになってしまいます。
これを避けたい場合、スーバークラスのNSStreamで用意されている非同期処理の機能を使います。非同期というのは同期の逆の意味ですが、要はこういうことです。同期の関数やメソッドは、それを呼び出すと処理(この場合は、ファイルからのデータの読み込み)が完了するかエラーが起こって失敗するまで呼び出し元に返ってこないのです。つまり、大量のデータを含むファイルを読み込もうとすれば、しばらく関数から戻ってこないことになります。当然、その間プログラムは別の処理をすることはできません。(ファイル読み込み処理に独占されてしまう)
これに対し、非同期の処理の場合、関数やメソッドは単に処理のきっかけを与えるにすぎません。つまり、関数を呼び出すとほとんどすぐに呼び出し元に返ってきます。でも、処理は完了していません。どういうことかというと、多くの場合はバックグラウンドで処理が動いていて、「必要に応じて、事前に指定したメソッドや関数を呼びにくる」のです。そのため、プログラムはファイルの読み込み処理をしている間、ずっとその処理に占有されてしまうこともなく、他の処理(多くは、ユーザーインターフェース関係など)を並行して行うことができます。当然、レインボーカーソルも回りません。
まあ、文章の説明だけではピンと来ないと思うので、具体的なコードに関しては次回ご紹介してみたいと思いますが、今回はもう1つのクラスのご紹介もしておきます。
NSFileHandleというクラスがそれですが、このクラスではNSInputStreamと同様、データを順次一定の量ずつ読み込むことや、すべてのデータを一気に読み込んでしまうことを同期的に行うこともできますし、また、それぞれを非同期に行うことも可能です。非同期に読み込む場合、一定量読み込む度にあらかじめ指定したメソッドを呼び出すようにすることもできますが、すべてのデータを読み込み終わった段階で初めて、指定したメソッドを呼び出すようにすることもできます。
この、「データを全て読み込み終わるまで、呼びにこない」というのはNSStreamにはない機能です。もっとも、NSStreamでは多少多めにコードを書く必要はあるものの、最終的に似たように処理になるようにすることは可能です。
では、NSStreamとNSFileHandleの処理の違いは何でしょう?
まずは、読み込んだデータをどのような形態で返してくるか、ということです。NSStreamは、読み込んだデータは単純にバイト列(unsigned charの配列)に格納されています。つまり、メモリに読み込んだデータを「そのまま」(*1)渡してきます。これに対し、NSFileHandleは、データをNSDataの形にして渡してくるのです。
NSDataもデータを格納する部分はバイト列なので、さほどの違いはないのですが、NSDataのオブジェクトになっていると、Objective-Cで使う場合には取り回しがラクになるというメリットはあります。もっとも、単なるバイト列も、NSDataの以下のメソッド
+ (id)dataWithBytes:(const void *)bytes length:(NSUInteger)lengthなどを使えば簡単にNSDataオブジェクトにすることはできます。
NSStreamとNSFileHandleのもう1つの違いは、非同期の処理を行う場合の手法の違いです。NSStreamではデリゲートという手法を使います。デリゲートというのはObjective-Cではよく使われる機能ですが、何らかの処理に際してデリゲートオブジェクトを設定しておくと、そのデリゲートオブジェクトが「特定の名前のメソッド」を持っていた場合、それを呼び出してくれるというものです。多彩な用途に使われるので、興味があったら研究してみるといいでしょう。
で、NSStreamのファイル読み込みでは、デリゲートオブジェクトが
- (void)stream:(NSStream *)theStream handleEvent:(NSStreamEvent)streamEventというメソッドを持っていると、ストリーム(*2)において何らかのイベント(状態の変化)が発生する度にこのメソッドを呼びにきます。当然、新しいデータを取得した場合にも呼び出されるので、ファイルを適当なかたまりごとに呼び出してくれるようになるわけです。
一方、これに対してNSFileHandleはノーティフィケーションという仕組みを使います。最近は、「ノーティフィケーションセンター」というのがiOSにもOS Xにもありますが、システム内部にはMac OS Xの最初からあった機能です。
ノーティフィケーションセンターというアプリ内の共通のオブジェクトに対して、あらかじめ「この名前のノーティフィケーション(通知)が来たら、このメソッドを呼んでね」と登録しておきます。これだけで、あとは登録を解除しない限り、通知が投げられたらそのメソッドを呼んでくれます。
この方法のいいところは、通知を投げる側はだれがこの通知に関心があるかとかを知っている必要がないところです。もともとシステム内では、数多くのさまざまな種類の通知が飛び交っていますが、だれもこの通知に関心がなければ、実際には通知が飛ぶだけで終わりです。
でも、例えば何らかの状態変化に連動して何かをしたいという場合、ノーティフィケーションセンターにメソッドの登録をすれば、その時点から処理を加えることができます。まあ、これも極めて頻繁に使われるiOS/OS Xの中心的な機能の1つですから、いろんな場面で使われています。
1つ例を挙げてみましょう。以下にコードだけを記載しますが、Cocoaのシンブルなアプリを作って、AppDelegateクラスを以下のようにするだけです。
=== AppDelegate.h ===
01: #import <Cocoa/Cocoa.h> 02: 03: @interface AppDelegate : NSObject { 04: 05: } 06: 07: - (IBAction)toggleCheckBox:(id)sender; 08: @end=== AppDelegate.m ===
01: #import "AppDelegate.h" 02: 03: @implementation AppDelegate 04: 05: - (IBAction)toggleCheckBox:(id)sender 06: { 07: NSButton *checkBox = sender; 08: if ([checkBox state] == NSOnState) { 09: [[NSNotificationCenter defaultCenter] addObserver:self selector:@selector(winMoved:) name:NSWindowDidMoveNotification object:nil]; 10: } 11: else { 12: [[NSNotificationCenter defaultCenter] removeObserver:self name:NSWindowDidMoveNotification object:nil]; 13: } 14: } 15: 16: - (void)winMoved:(NSNotification *)aNotification 17: { 18: NSBeep(); 19: } 20: 21: @endあとは、ウインドウをなければ1つ(か2つ)作って、いずれかのウインドウ上に1つチェックボックスを配置し、それを上記のクラスの-toggleCheckBox:に接続するだけです。
チェックを付けたり外したりしながら、ウインドウを動かしてみるとチェックが付いている時のみウインドウを移動させた後にビープ音が鳴るのが確認できると思います。
重要なのは、上記のクラスでは実際に通知(NSWindowDidMoveNotification)を投げてくるウインドウのことは全く触れていないということです。現に、ウインドウを複数作った場合、どのウインドウを動かしても同様にビープ音が鳴るはずです。もちろん、特定のウインドウのみを対象にしたい場合には、以下のようにメソッドの最後にそのウインドウを指定します。
=== AppDelegate.h ===(一部)
09: [[NSNotificationCenter defaultCenter] addObserver:self selector:@selector(winMoved:) name:NSWindowDidMoveNotification object:mainWindow];もちろん、このmainWindowというのは以下のようにヘッダにアウトレットを定義し、あらかじめいずれかのウインドウにつないでおく必要があります。
=== AppDelegate.h ===(部分)
03: @interface AppDelegate : NSObject { 04: IBOutlet NSWindow *mainWindow; 05: }
注1:一般にはこのようなデータを「生のデータ」(英語ではRaw Data)と言ったりします。
注2:ストリームとは小川のような水の流れた状態を表す言葉ですが、これをファイルのようにデータが順次流れてくるような仕組みを表現するのに使います。ファイルとかネットワークのように順次データが流れてくるものをストリームとして扱うクラスがNSStreamというわけです。 -
第219回 ファイルの扱いについて(3) 〜Objective-Cでのケース・1〜
この記事は、2013年09月25日に掲載されました。前回までCにおけるファイル読み込みについてお話ししました。
「Cにおける」と言いましたが、もう少し厳密に言うとCの言語そのものにファイルを扱うための機能はありません。なのでファイルの読み込みはANSI Cライブラリが提供する機能を利用することになります。もっとも、ANSI Cライブラリは「Cの標準ライブラリの位置付け」ですので、Cが使えるのにANSI Cライブラリを使えない状況はそんなに多くはありません。
ですので、「Cでファイルの読み込みを行う」と言えば、ANSI Cライブラリの機能で読み込むのだと思っておいて問題ないと思います。
では、Objective-Cでファイルを読み込むにはどうするのでしょうか。
Objectvie-Cにも標準ライブラリと言うべきものがあります。それはFoundationフレームワークと言います。Foundationフレームワークは、Objective-Cの基礎的な部分をも担う重要な仕組みであるため、実質的にFoundationフレームワークなしにObjective-Cを使うことはないと考えていいと思います。
ですので、これから解説する内容はObjective-CがFoundationフレームワークの機能を使って行っていることだと思っていてください。では、早速ファイルの読み込みの実例をお見せします。
01: #import <Foundation/Foundation.h> 02: 03: int main(int argc, const char * argv[]) 04: { 05: @autoreleasepool { 06: 07: NSString *filePath = @"~/Documents/37kagawa_rome.csv"; 08: filePath = [filePath stringByExpandingTildeInPath]; 09: NSError *error = nil; 10: NSString *fileContents = [NSString stringWithContentsOfFile:filePath 11: encoding:NSASCIIStringEncoding 12: error:&error]; 13: if (fileContents) { 14: printf("%s", [fileContents UTF8String]); 15: } 16: else { 17: NSLog(@"File Open Failed: %@", [error localizedDescription]); 18: } 19: } 20: 21: return 0; 22: }今回から遅ればせながらXcodeのバージョンを最新のもの(4.6.3)に合わせました(*1)。そのため、原則としてARC(Automatic Reference Counting)を使用した書き方になります。今回のコードでは顕著にその違いは出ていませんが、目立つのは
@autoreleasepool { ... }という部分。このコンパイラディレクティブ(@から始まるObjective-Cコンパイラに対して行う指示)が従来の
NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init]; ... [pool release];と同様のことを意味します。
さて、今回のプログラムは前回同様郵便番号のデータを用いますが、このファイルを現在のユーザーの「書類」フォルダの中に直接入れてあるという前提で書いてあります。
07: NSString *filePath = @"~/Documents/37kagawa_rome.csv";これがUNIXでの「ホームフォルダにあるDocumentsの中にある37kagawa_rome.csvというファイル」を示すパスの書き方(POSIXパス)ですが、先頭のチルダ記号はそのままではFoundationは処理できないので、この部分を展開つまり本来の正式な記述のフルパスに変換する処理を入れます。それが以下です。
08: filePath = [filePath stringByExpandingTildeInPath];そして、あとはファイルからデータをそのまま文字列の中に読み込みます。
少し正確に細かく書くと、文字列を扱うクラスであるNSStringの機能を使ってファイルの中身のデータをNSStringのインスタンスとして生成します。09: NSError *error = nil; 10: NSString *fileContents = [NSString stringWithContentsOfFile:filePath 11: encoding:NSASCIIStringEncoding 12: error:&error];ファイルからデータを読み込むための機能はFoundationにはたくさんありますが、とりあえずは最も簡単に使えるものを使ってみました。今回の使用例では、文字コードがASCIIであるとしてファイルの読み込みをしています。
基本的にはたったこれだけです。
ずいぶん簡単にできると思ったのではないでしょうか? 確かに、コードの記述量は少なく、簡単に使えるところがFoundationフレームワークの提供する機能の便利なところです。
もう少し踏み込んでみましょう。
今度は日本語を含むデータの読み込みを行ってみます。まずは単にコードのファイルの部分をさしかえたものです。使用するファイルは以下のところから取ってきました。
http://www.post.japanpost.jp/zipcode/dl/kogaki.html
01: #import <Foundation/Foundation.h> 02: 03: int main(int argc, const char * argv[]) 04: { 05: @autoreleasepool { 06: 07: NSString *filePath = @"~/Documents/37kagawa.csv"; 08: filePath = [filePath stringByExpandingTildeInPath]; 09: NSError *error = nil; 10: NSString *fileContents = [NSString stringWithContentsOfFile:filePath 11: encoding:NSASCIIStringEncoding 12: error:&error]; 13: if (fileContents) { 14: printf("%s", [fileContents UTF8String]); 15: } 16: else { 17: NSLog(@"File Open Failed: %@", [error localizedDescription]); 18: } 19: } 20: 21: return 0; 22: }さて、走らせてみてどうなったでしょうか? とりあえずファイルの読み込みはできましたが、表示がおかしいようですね。ファイルを差し替えただけで、コードの方は日本語への対応をしていなかったからです。
では、まずは文字コードの判定をFoundationに任せてみましょう。ってことで書き替えたのが下のコードです。
01: #import <Foundation/Foundation.h> 02: 03: int main(int argc, const char * argv[]) 04: { 05: @autoreleasepool { 06: 07: NSString *filePath = @"~/Documents/37kagawa.csv"; 08: filePath = [filePath stringByExpandingTildeInPath]; 09: NSError *error = nil; 10: NSStringEncoding usedEncoding; 11: NSString *fileContents = 12: [NSString stringWithContentsOfFile:filePath 13: usedEncoding:&usedEncoding 14: error:&error]; 15: if (fileContents) { 16: NSLog(@"Used Encoding: %@", 17: [NSString localizedNameOfStringEncoding:usedEncoding]); 18: 19: printf("%s", [fileContents UTF8String]); 20: } 21: else { 22: NSLog(@"File Open Failed: %@", [error localizedDescription]); 23: } 24: 25: } 26: 27: return 0; 28: }変わっている場所がごくわずかなので分かりにくいと思いますが、10行目と12行目です。前のコードでは文字エンコーディングをASCIIと指定していたのを今回は「お任せ」にして、読み込み後に、「どのエンコーディングを使用して読み込んだかを教えて!」というやり方になっています。
10: NSStringEncoding usedEncoding; 11: NSString *fileContents = [NSString stringWithContentsOfFile:filePath 12: usedEncoding:&usedEncoding 13: error:&error];で、実際に走らせてみると結果は、
File Open Failed: The file “37kagawa.csv” could not be opened because the text encoding of the contents could not be determined.ってことで、「エンコーディングを判断することができなかった」という結果になりました。「Foundationにお任せ」って言ったので、「文字コードの認識を自動でしてくれるのか」ってちょっと期待しちゃった方もおいでかもしれませんが、残念ながらそこはあまり期待できなさそうです。まあ日本語の処理なんて昔からこんなものです(笑)。ですので、素直にこちらからエンコーディングを指定するといたしましょう。
調べてみたところこの郵便番号のデータはシフトJISになっていたので、以下のようにすることでとりあえずは解決です。
01: #import <Foundation/Foundation.h> 02: 03: int main(int argc, const char * argv[]) 04: { 05: @autoreleasepool { 06: 07: NSString *filePath = @"~/Documents/37kagawa.csv"; 08: filePath = [filePath stringByExpandingTildeInPath]; 09: NSError *error = nil; 10: NSString *fileContents = [NSString stringWithContentsOfFile:filePath 11: encoding:NSShiftJISStringEncoding 12: error:&error]; 13: if (fileContents) { 14: printf("%s", [fileContents UTF8String]); 15: } 16: else { 17: NSLog(@"File Open Failed: %@", [error localizedDescription]); 18: } 19: 20: } 21: 22: return 0; 23: }さて、ここで疑問が湧いた方もいらっしゃるかもしれません。
「前のCでの読み込みの際は(データが格納される先は)charの配列だったけど、NSStringってのは何なの?」と。
NSStringというのは、Foundationで用意されている「文字列を格納し扱うためのクラス」で、Objective-Cにとってはなくてはならない要素です。また、これはObjective-Cの言語的にもサポートされていてリテラル表記も存在します。この連載でも既に何度も登場してきていますが、
@"Hello world"と書くと、これはそのままNSStringのインスタンスとなります。2012年に発表された「Modern Objective-C」と呼ばれる新しいObjective-Cにおいては、NSArrayやNSDictionary、NSNumberにもリテラル表記が設置されましたが、NSStringのリテラル表記は、Mac OS Xの最初の時から存在しています。
で、このNSStringですが、実際にどのような形でデータを格納しているかというと、「NSStringの内部データはUnicodeで格納されている」ということになります。
ではUnicodeとは何でしょうか? さすがにUnicodeという言葉を聞いたこともない人はこの連載を読んでいる方には多くないとは思います。ただ、「Unicodeとは?」と聞かれてそこを正しく説明できる人はプロのプログラマの中でも決して多くはないというのもまた実情だったりします。
Unicodeをきちんと説明するには、歴史的経緯や規格の話などにまで触れなければならないので、ここではとても無理です。なのでごく簡単な言葉でUnicodeを表現すると、「文字エンコーディング方式の一種で、世界中のすべての文字を同一のコード体系で表せることを目指した規格」となります。
ただ、これだと抽象的すぎて実際のデータを扱うためにはほとんど役に立たない説明なので、別の説明をします。
NSStringが保持しているデータは「UTF-16のデータの配列」です。UTFというのは、Unicodeの表現形式の1つで、UTF-8と共によく使われるものです。UTF-8はファイルに格納されたりネットワークでやり取りされたりする際に利用されることが多く、メモリ上で扱う際にはUTF-16であることが多いと思います。
8とか16というのは何かと言えば、それはデータを表現する場合に用いられる要素1つ当たりの大きさ(ビット数)です。文字列を表すためには、それぞれ配列を使うので、「配列の1要素の大きさ」と考えればいいでしょう。
ただ、この「要素」というのはそのまま1文字に対応するというわけではなく、特にUTF-8においては8ビットすなわち1バイト単位の要素が複数連なって1つの文字を表します。もちろん、1バイトで表せる文字もあって、それはいわゆるASCIIに対応する部分です。つまり、ASCIIで127(16進数で0x7F)までで表せる文字のみを使って構成されたデータの場合、ASCIIファイルとUTF-8ファイルは同一です(*2)。その代わり、128以上のデータを表そうとすると今度は3バイト以上が必要になるため、いわゆるシフトJISのデータに比べてファイルサイズが大きくなります(*3)。
これに対して、UTF-16では基本要素が2バイトなので、ASCIIのみのデータであっても倍のサイズが必要になってしまいますが、UTF-8に比べると1要素である16ビットで表せる文字の範囲が格段に広いため、多くのケースで「1文字=1要素」となります。なので、1要素で表せる範囲のみのデータを扱う場合に関しては、「文字数×2」が文字列サイズとなるため、任意の文字を取り出したりとかも字数を数えたりするとかが比較的容易になるのです。
さて、ちょっとUnicodeについての説明が長くなりましたが、要はNSStringではデータをUTF-16で保持しているわけです。と言うことは、元のファイル内にあったデータがUTF-16でなかった場合には、当然内部的に変換処理が行われることになります。変換がうまく行われなかった場合には、nilが返ります。
で、先ほど「文字コードの自動判別はできない」ということを言いました。もちろん、世の中には今までいろんな方々が築き上げてきた成果があり、それらを使用することで文字コードの判別は可能です。ただ、現時点ではFoundationフレームワークだけではそれをすることはできないようです(私の調査不足かもしれませんが)ので、とりあえず簡易的な方法として、この「変換ができなかった場合にはnilが返る」というのを利用します。
つまり、日本語のデータ表現に使用される主な文字エンコーディングであるシフトJIS、EUC、JIS(ISO-2022-JP)、UTF-8、UTF-16あたりを片っ端から試して、「変換できるものを探す」という方法です。
ただ、対象になるデータによっては先ほどのUTF-8とASCIIが全く同一となる場合もあるように、「どのエンコーディングだか判別不能」ということもあるので、それぞれのエンコーディングの表現方法を調べて、特徴を洗い出せば「どういう順序で試していけば、正解にたどり着けるのか」ということが分かるかもしれませんが、そこはここでは扱わず、とりあえずすべてのエンコーディングで試して、変換の成否を調べてみることにします。
今までの流れを受けると、以下のようなプログラムが書けるかと思います。
01: #import <Foundation/Foundation.h> 02: 03: int main(int argc, const char * argv[]) 04: { 05: @autoreleasepool { 06: 07: NSString *filePath = @"~/Documents/37kagawa.csv"; 08: filePath = [filePath stringByExpandingTildeInPath]; 09: NSError *error = nil; 10: 11: NSStringEncoding encodings[] = { 12: NSShiftJISStringEncoding, 13: NSJapaneseEUCStringEncoding, 14: NSISO2022JPStringEncoding, 15: NSUTF8StringEncoding, 16: NSUTF16StringEncoding 17: }; 18: 19: for (int i = 0; i < 5; ++i) { 20: NSString *fileContents = 21: [NSString stringWithContentsOfFile:filePath 22: encoding:encodings[i] 23: error:&error]; 24: if (fileContents) { 25: NSLog(@"File content converted successfully with %@", 26: [NSString localizedNameOfStringEncoding:encodings[i]]); 27: } 28: else { 29: NSLog(@"File Open Failed: %@", [error localizedDescription]); 30: } 31: } 32: 33: } 34: 35: return 0; 36: }まあ、これでもいいと言えばいいのですが、実はデータを毎回ファイルから読み込もうとしている部分は無駄な感じがします。要は効率が悪いのです。
通常こういう場合には、ファイルからのデータを一度NSDataに読み込み、そこからNSStringへの変換を試みるという形を取ります。コードは以下のようになります。
01: #import <Foundation/Foundation.h> 02: 03: int main(int argc, const char * argv[]) 04: { 05: @autoreleasepool { 06: 07: NSString *filePath = @"~/Documents/37kagawa.csv"; 08: filePath = [filePath stringByExpandingTildeInPath]; 09: NSError *error = nil; 10: 11: NSStringEncoding encodings[] = { 12: NSShiftJISStringEncoding, 13: NSJapaneseEUCStringEncoding, 14: NSISO2022JPStringEncoding, 15: NSUTF8StringEncoding, 16: NSUTF16StringEncoding 17: }; 18: 19: NSData *data = [NSData dataWithContentsOfFile:filePath 20: options:0 error:&error]; 21: if (data == nil) { 22: NSLog(@"File Open Failed: %@", [error localizedDescription]); 23: 24: return 1; 25: } 26: 27: for (int i = 0; i < 5; ++i) { 28: NSString *fileContents = 29: [[NSString alloc] initWithData:data 30: encoding:encodings[i]]; 31: if (fileContents) { 32: NSLog(@"File content converted successfully with %@", 33: [NSString localizedNameOfStringEncoding:encodings[i]]); 34: } 35: } 36: 37: } 38: 39: return 0; 40: }前に試したように、このファイルはシフトJISであることが分かっているにも関わらず、JISにもUTF-16にも変換できているように見えます。しかし、実際にfileContentsの中身を確認してみれば正しく変換できているのはシフトJISだけだと分かります。
ではなぜ、JISやUTF-16にも変換「できているかのように」見えるのでしょうか? 実は、「正しく変換できている」の意味するのはあくまでそれぞれの文字エンコーディング的に矛盾がない、ということだけであって、「正しいデータ」つまり今回のデータならば日本語として正しく読める文字列になっているということであるとは限らないのです。
注1:と思ったら、Xcode 5が出てしまいましたね。私はまだ実際に試してはいませんが、今のところコードは特に変更もなくXcode 5でも利用できると思います。
注2:例えば16進数表記で41 42 43と3バイトのデータを持つファイルがあった場合、これは文字列ABCを持ったASCIIコードのファイルであるとも言えるし、UTF-8のファイルであるとも言えるというわけです。
注3:「123あいう」というテキストをシフトJISで保存するとファイルサイズは9バイトになりますが、UTF-8で保存すると12バイトになります。ちなみにUTF-16だと14バイトとなります。これは、シフトJISでは1 + 1 + 1 + 2 + 2 + 2で9バイト、UTF-8では1 + 1 + 1 + 3 + 3 + 3で12バイトということで、UTF-16の場合、文字列データ自体は2 + 2 + 2 + 2 + 2 + 2で12バイトなのですが、ファイルに保存される場合先頭にBOM(Byte Oreder Mark)と呼ばれる識別子が入るため、14バイトになるのです。 -
第218回 ファイルの扱いについて(2)
この記事は、2013年07月25日に掲載されました。前回は、ファイルからデータを行単位で読み込むためにはどうしたらいいか、という話の途中で終わりました。早速続けます。
やり方にはいくつか考えられるのですが、以下の三つを挙げてみました。
- fgetc()などで1バイトずつ読み出し、改行コードを判定しながら処理
- fread()で特定のサイズごとに読み出し、行を構成する
- ファイルの内容を一気に読み込み、行ごとに切り出しをする
fgetc()で1バイトずつ読み出す方法ですが、これはあまり処理効率がよくありません。というのは、まずデータをテキストとして処理する場合、バイト単位で扱うのはあまり得策ではないからです。
と申しますのはこういうことです。まず改行の話。前回お話ししたように、一般的にテキストファイルでは改行コードには3種類あります。いわゆるMacのCRやUnixのLFは1バイトで改行を表現することになっているのに対して、Windows/DOSでは「CRとLFが連続すると改行コード」ということになっています。
この場合、1バイトずつ処理するfgetc()を使ったやり方ですと、改行コードを識別するためには、fgetc()を2回呼ぶ必要があります。つまりfgetc()がCRを返した場合に、次がLFであるかを判断して、そうだった場合にそこで初めて改行とする、ということです。
でも、これは最初からこのファイルの改行コードがCR+LFであると決まっている場合の話であって、そもそも対象のファイルの改行コードがCRなのかLFなのかCR+LFなのかが分からない場合にはまた話が違ってきます。
さらに、ファイルを構成するテキストがASCII文字に限定されない場合は、処理はさらに面倒になってきます。(日本語などのいわゆるマルチバイトを扱うケースについては近いうちに解説します)
そんなわけですので、fgetc()を使ってバイトごとに処理をするアプローチはあまり適してはいないと思われます。
次に、fread()を使用してブロックごとに読み出す方式ですが、これの最大の難点は「1行あたりのバイト数が分からない」ということです。fread()を使用する場合、常に読み込むためのバッファとなるメモリ領域を使用することとなりますが、このメモリ領域は大きさが固定となるため、これがどんな状況下においてもファイル内の1行とサイズが合致するわけではありません。ですので、このバッファに読み込んだデータを切り貼りして行として再構成する必要が出てくるのです。
ここまで読んできて、もうお分かりでしょうが、私としてお勧めしたいのは3番面のファイルをまるごと読み込んできて処理をする方法です。私も何だかんだでもう20年ぐらいはプログラミングをしてきていますが、私がCでプログラムを書き始めたころはこの方法はほとんど使われませんでした。
というのもメモリの状況が、当時は今と比べると格段に貧弱で、たとえテキストファイルであっても、ファイルのデータをまるごとメモリに読み込むなどということはあまり現実的なやり方ではなかったのです。ですが、今は時代が違います。メインメモリですらGBの単位であるのは当たり前ですし、OSが仮想メモリという仕組みをサポートしていますから、数メガ程度(と今の時代ならば言ってしまえる!)のテキストファイルならば、そのままサクッとメモリに読み込んでしまっても何の問題もありません。
メモリに読み込んでしまった状態であれば、そのデータのどの部分にでも簡単にアクセスできますから、いろいろと便利です。もちろん、何らかの事情で相当大きなデータ(例えば、大規模のデータベースの内容をダンプしたファイルなど)となると事情は違ってくるかもしれませんが、大概のテキストファイルであれば、今はこのアプローチで行けるのではないかと私は思います。
では、具体的にコード例を示してみましょう。
01: #include <stdio.h> 02: #include <stdlib.h> 03: 04: int main(void) 05: { 06: const char file_name[] = "37kagawa_rome.csv"; 07: FILE *fp = fopen(file_name, "rb"); 08: if (fp == NULL) { 09: fprintf(stderr, "Can not open file: %s\n", file_name); 10: return 1; 11: } 12: 13: // ファイルのサイズを調べる 14: fseek(fp, 0, SEEK_END); 15: int file_size = ftell(fp); 16: rewind(fp); 17: 18: char *ptr = malloc(file_size + 1); // 1バイト余計に確保している理由はあとで説明 19: if (ptr == NULL) { 20: fprintf(stderr, "Memory error.\n"); 21: fclose(fp); 22: return 1; 23: } 24: 25: fread(ptr, 1, file_size, fp); 26: fclose(fp); 27: 28: ptr[file_size] = '\0'; // これが、1バイト余計に確保した理由 29: 30: printf("%s", ptr); 31: 32: free(ptr); 33: 34: return 0; 35: }行の処理までは、まだやっていません。また、このプログラムは、ファイルの中の文字列データがヌル文字を含んでいないことを前提にしています。含んでいた場合には、うまく処理ができません。通常はテキストファイルにはヌル文字は含まれないと思いますが、まれに含まれるものもあるのです。
で、とりあえずはメモリ上にファイルの中身を読み込んでみたわけです。簡単にやっていることを説明しますと、fopen()でファイルをバイナリモードで開いた[7行目]のち、fseek()という関数を使って、ファイル位置指示子をファイルの末尾まで進めます。[14行目]
そこでftell()という関数を呼び出す[15行目]と、ファイル位置指示子がファイルの先頭から何バイト離れた位置にあるかを返すので、これがすなわちこのファイルのバイト数(サイズ)ということになるわけです。
ファイル位置指示子はrewind()という関数を使ってファイルの先頭に戻しておきます[16行目]。rewindすなわち「巻き戻し」ですね。
次に、メモリの確保です。いま取得したバイト数分のメモリをmalloc()を使って動的に確保します[18行目]が、後で文字列として扱い易いように末端にヌル文字を入れておくので、1バイト多めに確保します。
次に、データの読み込みです。fread()の第3引数にファイルのサイズをそのまま渡して、一気にメモリの中にファイルのデータを読み込みます。[25行目]
読み込んだら、ファイルはもう不要なので、fclose()で閉じておきましょう。[26行目]
そして、末尾にヌル文字を追加して[28行目]、読み込みがうまく行ったかどうかを確認するために表示してみます。ファイル全体が1つの文字列として一気に表示されるはずです。[30行目]
用が済んだら、動的に確保したメモリーはfree()で解放します。[32行目]
参考までに、今回テストに使ったファイルは、「37kagawa_rome.csv」となっていますが、これは郵便番号データを利用してみました。
http://www.post.japanpost.jp/zipcode/dl/roman.html
のページからいちばんサイズの小さかった香川県のものをダウンロードしてきて利用しています。
さて、いかがですか? そんなに難しくはないと思います。では、次にこのデータを行ごとに分割する処理を加えてみましょう。基本的な方針としては、新たに配列を1つ用意して、その中に各行を納めます。ただし、ファイルの内のデータは既にメモリー上に読み込まれていますから、それをそのまま利用してみたいと思います。
あくまで一例ですが、こんな感じに処理してみました。
01: #include <stdio.h> 02: #include <stdlib.h> 03: 04: int main(void) 05: { 06: const char file_name[] = "37kagawa_rome_lf.csv"; 07: FILE *fp = fopen(file_name, "rb"); 08: if (fp == NULL) { 09: fprintf(stderr, "Can not open file: %s\n", file_name); 10: return 1; 11: } 12: 13: // ファイルのサイズを調べる 14: fseek(fp, 0, SEEK_END); 15: int file_size = ftell(fp); 16: rewind(fp); 17: 18: char *data_ptr = malloc(file_size + 1); 19: if (data_ptr == NULL) { 20: fprintf(stderr, "Memory error.\n"); 21: fclose(fp); 22: return 1; 23: } 24: 25: fread(data_ptr, 1, file_size, fp); 26: fclose(fp); 27: 28: data_ptr[file_size] = '\0'; 29: 30: size_t line_count = 1024; 31: char **lines = malloc(sizeof(char *) * line_count); 32: if (lines == NULL) { 33: fprintf(stderr, "memory full.\n"); 34: free(data_ptr); 35: return 1; 36: } 37: 38: char *ptr = data_ptr; 39: int index = 0; 40: lines[index++] = ptr; 41: lines[index] = NULL; 42: while (*ptr != '\0') { 43: if (*ptr == '\r' || *ptr == '\n') { 44: if (*ptr == '\r' && *(ptr + 1) == '\n') { 45: *(ptr + 1) = '*'; 46: ++ptr; 47: } 48: 49: *ptr = '\0'; 50: 51: if (line_count < index + 2) { 52: line_count *= 2; 53: lines = realloc(lines, sizeof(char *) * line_count); 54: if (lines == NULL) { 55: free(data_ptr); 56: return 1; 57: } 58: } 59: 60: lines[index++] = ptr + 1; 61: lines[index] = NULL; 62: } 63: 64: ++ptr; 65: } 66: 67: for (int i = 0; lines[i] != NULL; ++i) { 68: printf("[%03d]: %s\n", i, lines[i]); 69: } 70: 71: free(lines); 72: free(data_ptr); 73: 74: return 0; 75: }付け加えた部分を中心に解説してみます。
重要な部分は、31行目で定義しているlinesという変数です。この変数はポインタとして定義してありますが、これは「文字列の配列」として利用するためのものです。仮にファイルの中の行数が20行あるとして、各行ごとにそれぞれ100バイトを割り当てたとすると、配列の定義は以下のようになります。
char lines[20][100];ですが上記のコードでは、この変数を単に
char **lines;と定義しています。ですが動的にメモリブロックを確保して、その先頭のアドレスをこのlinesに割り当て、さらに以下のコードで各行の先頭に当たる位置をメモリ上に納めることによって、文字列の配列として使用することが可能になるのです。
この辺の具体的な話に関しては今回のテーマから外れるので割愛しますが、興味のある方は是非ご自分で研究してみてください。
話を戻します。
42行目からのループが、ファイルから読み込んだデータを解析して「各行の頭の部分」を探し出しているところです。ここでは改行コードがCRでもLFでもCR+LFでも大丈夫なように処理していますが、例えば最初からCR+LFであるという前提でいいのであれば、このコードの38行目から65行目の部分を以下のようにさしかえることが可能です。
38: char *ptr = data_ptr; 39: int index = 0; 40: lines[index++] = data_ptr; 41: lines[index] = NULL; 42: char *ptr = strstr(data_ptr, "\r\n"); 43: while (ptr != NULL) { 44: *ptr = '\0'; 45: *(ptr + 1) = '*'; 46: 47: if (line_count < index + 2) { 48: line_count *= 2; 49: lines = realloc(lines, sizeof(char *) * line_count); 50: if (lines == NULL) { 51: free(data_ptr); 52: return 1; 53: } 54: } 55: 56: lines[index++] = ptr + 2; 57: lines[index] = NULL; 58: 59: ptr = strstr(ptr + 2, "\r\n"); 60: }ところで、ループの中でline_countという変数を操作している部分がありますが、これはデータに行がいくつ含まれるか分からないので、とりあえず最初に1024としておいて、動的に確保しています。
そもそも、linesという変数が保持するのはメモリ上に読み込まれたファイルのデータの中の各行の先頭位置を指すポインタなので、データとしてはポインタの配列となります。一行増えるごとにrealloc()で「配列」のサイズを増やしていくやり方もありですが、メモリアロケーションを頻繁に行うとちょっと重くなるので、多少のムダが出ることは承知で「足りなくなったら、2倍にする」という増やし方をしています。
それと、ループの中で改行位置を見付けたらそれをヌル文字に置き換えています。こうしないと、文字列が全部つながったままになってしまうので。改行位置をヌル文字に置き換えることによって、各行の先頭位置を文字列として使うと行単位で扱えるというわけです。
ちなみにCR+LFの場合、CRをヌル文字に置き換えればそれで充分なのですが、デバッグの都合上LFの位置にはアスタリスクを入れてみました。
さて、こんな感じで、ファイルのデータをまるごとメモリに読み込み、なおかつ行単位で配列として扱うことができるようになりました。ついでですので、皆さんがご自分のプログラムに応用できるように、少し汎用性を持たせて関数に切り分けたものもご紹介します。
01: #include <stdio.h> 02: #include <stdlib.h> 03: 04: char *file_read(const char *file_name); 05: char **get_lines(char *data_ptr); 06: 07: int main(void) 08: { 09: const char file_name[] = "37kagawa_rome.csv"; 10: 11: char *data_ptr = file_read(file_name); 12: if (data_ptr == NULL) { 13: fprintf(stderr, "Failed to read file.\n"); 14: return 1; 15: } 16: 17: char **lines = get_lines(data_ptr); 18: if (lines == NULL) { 19: fprintf(stderr, "Failed to get lines.\n"); 20: free(data_ptr); 21: return 1; 22: } 23: 24: for (int i = 0; lines[i] != NULL; ++i) { 25: printf("[%03d]: %s\n", i, lines[i]); 26: } 27: 28: free(lines); 29: free(data_ptr); 30: 31: return 0; 32: } 33: 34: char *file_read(const char *file_name) 35: { 36: FILE *fp = fopen(file_name, "rb"); 37: if (fp == NULL) { 38: // fprintf(stderr, "Can not open file: %s\n", file_name); 39: return NULL; 40: } 41: 42: fseek(fp, 0, SEEK_END); 43: int file_size = ftell(fp); 44: rewind(fp); 45: 46: char *data_ptr = malloc(file_size + 1); 47: if (data_ptr == NULL) { 48: // fprintf(stderr, "Memory error.\n"); 49: fclose(fp); 50: return NULL; 51: } 52: 53: fread(data_ptr, 1, file_size, fp); 54: fclose(fp); 55: 56: data_ptr[file_size] = '\0'; 57: 58: return data_ptr; // 呼び出し元で解放すること 59: } 60: 61: char **get_lines(char *data_ptr) 62: { 63: size_t line_count = 1024; 64: char **lines = malloc(sizeof(char *) * line_count); 65: if (lines == NULL) { 66: // fprintf(stderr, "memory full.\n"); 67: return NULL; 68: } 69: 70: char *ptr = data_ptr; 71: int index = 0; 72: lines[index++] = ptr; 73: lines[index] = NULL; 74: while (*ptr != '\0') { 75: if (*ptr == '\r' || *ptr == '\n') { 76: if (*ptr == '\r' && *(ptr + 1) == '\n') { 77: *(ptr + 1) = '*'; 78: ++ptr; 79: } 80: 81: *ptr = '\0'; 82: 83: if (line_count < index + 2) { 84: line_count *= 2; 85: lines = realloc(lines, sizeof(char *) * line_count); 86: if (lines == NULL) { 87: return NULL; 88: } 89: } 90: 91: lines[index++] = ptr + 1; 92: lines[index] = NULL; 93: } 94: 95: ++ptr; 96: } 97: 98: return lines; // 呼び出し元で解放すること 99: } -
第217回 ファイルの扱いについて(1)
この記事は、2013年05月31日に掲載されました。前回、前々回はそれまで続けてきた「Objective-Cから始めるプログラミング」というテーマを一時外れ、関数と配列とポインタの関係についてお話ししました。
約束通りに行くと、今回はまた元の路線に戻って「〜Objective-CにCの知識は不要?・2〜」といった感じになるわけですが、連載の頻度も落ちていることですし、悠長に「知識が必要? 不要?」などと論じているより、具体的な話を展開していった方が有益だろうと考えました。で、具体的な話の方向としては、あまりObjective-CとかC言語とかの枠にとらわれず、「C言語を含んだ形で成り立っているObjective-C」という観点から、プログラミングにおいて使用される個々の技術項目を解説してみるということで行こうと思います。
さて、これから何回かにわたってお話しするのは、ファイルの扱いについてです。長いこと続けてきたこの連載ですが、ファイルの扱いについて触れた記憶がありません。もしかしたら、何かのついでにファイルを扱うこともあったかもしれませんが、少なくともファイル処理をテーマとして正面からとらえたことはなかったように思います。
これからのお話では、そのファイルについてCやObjective-Cで扱う場合にどのようなやり方があるのかを考えてみたいと思います。
ところで、この連載をお読みの皆さんならファイルというのがハードディスクやSSDの中に「物体として存在」しているのでないことはご存知でしょう。OSが提供する「ファイルシステム」というものが、メディアの中のデータを特定のまとまりとして表現しているもの、それがファイルという概念なわけです。
しかしながら、プログラミングにおいてもこのファイルという概念は有効です。ディスクドライバなどの低レベルなプログラミングならばそうとも限りませんが、通常のアプリケーションプログラミングにおいては、ファイルというのはデータを永続的に保管しておいてくれる物体ととらえて何ら問題はありませんし、ファイルを扱うことでプログラミングの可能性は広がります。
これからObjective-CとCでのファイルの扱いについて見ていくわけですが、Mac OS XはUNIXですので、OSの深い部分ではファイルなどの処理は「システムコール」という仕組みを使って実装されています。システムコールは、OSが提供している機能で、マシン語レベルで呼び出すことのできるものですが、Cで呼び出すことも可能です。
この連載の範囲としてはシステムコールに踏み込むことはしないのですが、基本的にObjective-CでもCでも、ファイルを扱う処理の根底ではこのシステムコールが動いていると考えてよいでしょう。
ところで、ファイルには「テキストファイル」と「バイナリファイル」とがあるのはご存知かと思います。では、これらの違いは何なのでしょう?
実はほとんど違いはありません。基本的にはファイルを構成するデータがすべて何らかの文字コード(空白やタブや改行などの制御記号も含む)のみで成り立っているものをテキストファイルと呼び、それ以外のものをバイナリファイルと呼びますが、これらは相反する関係ではなく、すべてのファイルはバイナリファイルであり、バイナリファイルの一部のものをテキストファイルと呼んでいるだけのことです。
ただ、ANSI Cにおいては、一部のファイルを扱う関数群が「テキストモード」と「バイナリモード」という区別をするケースがあります。これは、後で触れる3種類の改行コードの違いを吸収するために用意された機能ですが、今の時代、例えばMacで扱うテキストファイルはすべてMac上で作られたものに限るなんてことはあり得ないので、このテキストモードという考え方自体が既に時代にそぐわないものになってきていると思います。
C言語でファイルを扱う場合、最初は以下のようなやり方をすることが多いでしょう。
01: #include <stdio.h> 02: 03: int main(void) 04: { 05: const char *filename = "/Users/someone/ANSI C project/test.txt"; 06: FILE *fp = fopen(filename, "r"); 07: if (fp == NULL) { 08: fprintf(stderr, "File not found!\n"); 09: return 1; 10: } 11: 12: int c = fgetc(fp); 13: while (c != EOF) { 14: fputc(c, stdout); 15: 16: c = fgetc(fp); 17: } 18: 19: fclose(fp); 20: 21: return 0; 22: }基本となるのはfopen()という関数で、この関数はファイルのパスとオープンモードを引数に取り、ファイルのオープンが正常にできた場合、FILE構造体へのポインタを返します。
ファイルのパスは、UNIXの扱いに慣れている人ならばおなじみの指定方式ですが、Mac OS XではPOSIXパスと呼ばれます。絶対パスと相対パスでの指定が可能で、絶対パスというのは常にルート(UNIXではファイル階層の最上位を/で表す)からのパスで、相対パスというのは、カレントディレクトリ(Xcodeから実行した場合、たぶん実行ファイルのある場所。getcwd()という関数を使うと確認可能)からの位置関係で表すパスです。
例として、ユーザー名がsomeone、プロジェクトのフォルダ名がSimpleANSI_Cだとしましょう。この時に、プロジェクトフォルダの直下にあるtest.txtという名のファイルを示すパスは、
絶対パス:/Users/someone/SimpleANSI_C/test.txt 相対パス:../../test.txt
となります。相対パスは前述の通りに実行ファイルの位置がカレントディレクトリであるという前提での相対的な位置関係を示します。実行ファイルは/Users/someone/SimpleANSI_C/build/Debug/にあると考えてください。
UNIXでは、ピリオド1つがカレントディレクトリを表し、ピリオド2つが親ディレクトリ(1つ上の階層)を表しますので、上記の相対パスの例では、実行ファイルのあるディレクトリであるDebugの上の階層であるbuildのさらにまた上の階層であるSimpleANSI_Cの中にあるtest.txtを示すと解釈されるわけです。
次にオープンモードです。fopen()のリファレンスを見ると、何やらいろんなモードを指定可能なように見えますが、読み取り専用でオープンする場合には、”r”か”rb”のどちらかを指定します。
この2つのオープンモードの違いは何かというと、”r”はテキストモードで”rb”はバイナリモードということになります。
そこで、テキストモードとバイナリモードの違いは何かということになるわけですが、パソコンの世界では改行コードは以下の三種類があります。
UNIX: LF(0x0A) MAC: CR(0x0D) Windows/DOS:CR+LR
注意すべき点は、WindowsがCR(0x0D)とLF(0x0A)と、2つの連続したバイト列であることと、MacでのCRはあくまでも「以前の形式」であるということです。MacではMac OS Xになる前は改行コードはCRでしたが、Mac OS XになってUNIXとなったことから改行コードはLFになりました。ただ、以前のMac OSのバージョンとの互換環境であるCarbonでは原則としてCRなので、結果的にMac OS XにおいてはCRのケースとLFのケースが混在しているのです。
また、CR+LFはWindowsの改行コードであると同時に、HTTPなどのインターネットにおけるデータのやり取りのプロトコルの多くでも採用されているため、仮に「私はMac上ではWindows/DOSのファイルは一切扱わない」と言う人であっても、結局のところMac OS Xのプログラミングをする場合、上記の3種類の改行コードのいずれにも遭遇する可能性があるのです。
それでは、ファイルをテキストモードで開くのとバイナリモードで開くのとでは何が違うのかと言いますと、実は改行コードの「自動変換」をしてくれるか否か、だけの違いです。
もともとUNIXの世界で生まれたC言語において改行コードが’\n’と表現されることはご存知かと思いますが、この’\n’はLFです。ちなみにCRは’\r’となり、CR+LRは、’\r’, ‘\n’という具合になります。
ファイルからデータを読み込む時、例えば行単位でメモリに読み込んでくるような場合にはC言語では改行コードはLFであることを前提として動作するため、もし改行コードがLFでない環境の場合には行の区切りが分かりません。そのため、例えばWindows/DOS上でテキストファイルを処理する時、テキストモードで開いてやればCR+LFを自動的にLFに置き換えて処理してくれるということなのです。
もしかして、この「自動的に置き換えてくれる」というところで、「お、それは便利だな」と思った方がおいでかもしれませんが、残念ながらそんなに便利なものではありません。というのは、これはあくまでも「Windows上で動作する場合は、CR+LFがLFに置き換えられ、(昔の)Mac上で動作する場合はCRがLFに置き換えられる」というだけの話であって、例えばMac上でWindowsのテキストファイルを開いても自動的にCR+LFをLFに置き換えてくれるといったような機能ではないのです。
つまり、インターネットを介してだれでもが簡単に各種OS間でデータを自在にやり取りできる時代が来るなどとは想像すらしていなかったころに作られた仕組みですから、残念ながらOS間での改行コードの違いを吸収してくれるような仕組みなどではありません。今どきのプログラマで扱うデータは常に単一のOSに閉ざしたものに限られているなどという人はまずいないでしょうから、もう最初からこのテキストモードなんてものはなかったものと考えておいた方がかえって気がラクです(笑)。
で、「なかったものとして」とか言いましたが、もう少しテキストモードの話を進めます。
ここでいったん立ち止まって、ANSI Cにおけるファイルの読み込みにはどのようなやり方があるかを一覧します。
まず、ファイルを読み込む場合、ファイル内のデータへのアクセス方法は大きく分けて以下の二通りがあります。
- シーケンシャル
- ランダムアクセス
シーケンシャルというのは、連続的にというような意味ですが、ファイルを先頭から順に読んでいく方式です。対してランダムアクセスというのは、ファイル内の任意の位置からデータを読み出す方式です。
また、上記とは別にデータの読み出し方には以下の三つがあります。
- 文字(バイト)単位
- 行単位
- ブロック単位(固定長読み出し)
バイト単位で読み出すことを「文字単位」と言っているのは、Cにおいて1バイトを表す型がcharしかないこととも関係していますが、「1文字=1バイト」という考え方が通用していたころの名残りと考えてください。じゃあ、例えば1文字が2バイトの場合(UTF-16の一部とシフトJISの日本語部分)にはどうするかと言えば、1バイトずつ連続して読み込んだデータを結合するか、ブロック単位読み出しで2バイトを読み込むかです。
ブロック単位読み出しというのは、「決めたサイズの分だけ読み出す」ことで、charとかintなどのプリミティブ単位のデータ、任意の構造体、さらには配列に読み出すこともできます。後で紹介しますが、ファイル内の全部のデータを一気に読み出す場合にもこれを使います。残った「行単位での読み出し」ですが、これは先ほどから話しているテキストモードと関連します。行で読み出すということは基本的に改行コードすなわちLFまでのデータを読み出すのですが、この行単位読み出しに使用する関数であるfgets()を少し細かく見てみます。
リファレンスを見ると、fgets()のプロトタイプは以下のようになっています。
char *fgets(char *s, int n, FILE *stream);
三つの引数を取り、最初の引数は読み出したデータを格納するメモリ位置を指すポインタ、第二引数は読み込むサイズの上限、第三引数は読み出し元のファイルを示すポインタとなっています。
動作としては、ファイルの「現在の位置」から以下のいずれかの条件を満たすまで、連続してデータを読み込んで、sが示すメモリ位置から書き込んでいきます。
- 改行コードに達する
- ファイル末尾に達する
- 指定サイズ(第二引数で指定した値マイナス1)分を読み出した
そして、末尾には’\0′を付加します。
ここで、先ほど話した「改行とは」という話が絡んできます。例えば、Windows上で作られたテキストファイルをMacで開いたとします(当然、fopen()に”r”指定をしたということです)。この時、テキストモードにより発生する「改行コード変換」は、CRをLFに変換する処理になります(*注)。しかし、Windowsで作られた改行コードはCR+LFの2バイトですから、結果的にLF+LFということになり、処理した結果は、「何故か一行ごとに空行が入ってしまう」というバグとして表れたりするわけです。このようなわけで、テキストモードというのはもはや今の時代的にはそんなにありがたい機能でもありません。となると、「最初からテキストモードなどというものはないと思っておく」というのもアプローチとしてはありなのではないでしょうか。
で、テキストモードを諦めるとなると、まずfgets()などの関数は使い物にならなくなりますから、プログラムは以下のような感じになってきます(あくまでも一例です)。
01: #include <stdio.h> 02: 03: int main(void) 04: { 05: const char *filename = "/Users/some/Desktop/test.txt"; 06: 07: FILE *fp = fopen(filename, "rb"); 08: if (fp == NULL) { 09: fprintf(stderr, "File not found!\n"); 10: return 1; 11: } 12: 13: char buffer[BUFSIZ]; 14: size_t bytesRead = fread(buffer, 1, sizeof(buffer), fp); 15: while (0 < bytesRead) { 16: fwrite(buffer, 1, bytesRead, stdout); 17: 18: bytesRead = fread(buffer, 1, sizeof(buffer), fp); 19: } 20: 21: fclose(fp); 22: 23: return 0; 24: }このプログラムでは、行というものは一切考慮していません。固定長のバッファを用意し、fread()というブロック読み出しに使用する関数を使用して、BUFSIZ分の長さごとにファイルからデータを読み出して、stdoutに書き出しています。このfread()という関数のプロトタイプは以下のようになっています。
size_t fread(void *ptr, size_t size, size_t nitems, FILE *stream);
引数は、四つ。最初は読み出したデータを格納するメモリを指すポインタ、最後の引数は読み出し元のファイルポインタというところはfgets()と同様です。違うのは第二、第三の引数。ここは配列を指定し易いように2つに分けてあり、第二引数が配列の一要素のサイズで、第三引数が配列の要素数ということになります。
上記のプログラム例では、第二引数は1になっていますが、これは配列bufferの要素であるcharのサイズが1であるということを意味しています。結果として、第二引数と第三引数をかけた値がファイルから読み出されるデータのサイズ量ということになります。
ただ、指定しただけの容量が既にファイルに残っていない場合(最初からそんな容量ほどのデータがなかったとか、現在の読み出し位置からファイル末尾までのサイズがそんなにはない場合)には当然指定した容量のデータを読み出すことはできません。それを検知するのが、この関数の返す値です。関数から返ってくる値が「実際に読み出せたデータのサイズ」を表しますので、もし指定したよりも小さい値が返ってくれば、結果的にファイルの末尾に到達したのだということが分かります。
では、もし行単位での読み込みをしたい場合にはどうしたらいいでしょうか? やり方はいくつか考えられます。
- fgetc()などで1バイトずつ読み出し、改行コードを判定しながら処理
- fread()で特定のサイズごとに読み出し、行を構成する
- ファイルの内容を一気に読み込み、行ごとに切り出しをする
他にもあるかもしれませんが、まあだいたいこんなところでしょう。次回は、この辺からお話を続けていきます。
注:ここの記述は、実は正確ではありません。Mac OS XにおいてANSI Cのプログラムを書き、それをgccでコンパイルした場合(恐らくllvmでも)、これ純然たるUNIX環境ですから、CRがLFに変換されることはなく、単にLFがLFに変換されるだけです。つまり、UNIX環境においてはテキストモードとバイナリモードの違いは「ない」ということなのです。 -
第216回 関数と配列とポインタの関係〔後編〕 〜配列・構造体・ポインタ〜
この記事は、2013年03月26日に掲載されました。さて、前回の記事では「Cでは参照渡しという概念がなく、値渡ししかできないので、配列を渡すとそれは自動的に先頭要素を指すポインタに置き換えられる」といったようなことをお話ししました。
では、なぜ配列はポインタに置き換えられてしまうのでしょう?
ここで、「配列を値渡しで渡すとどうなるのか?」という実験をしてみます。前回予告した「スペシャルテクニック」(笑)の登場です。
では早速、コードをご覧いただきましょう。
01: #include <stdio.h> 02: #include <ctype.h> 03: 04: struct String { 05: char s[4096]; 06: }; 07: 08: struct String convert_lower2upper(struct String str); 09: 10: int main(void) 11: { 12: struct String str1 = { "My sister Mary is 11 years old." }; 13: struct String str2; 14: 15: printf("Before: %s\n", str1.s); 16: 17: str2 = convert_lower2upper(str1); 18: 19: printf("After: %s\n", str2.s); 20: 21: return 0; 22: } 23: 24: 25: struct String convert_lower2upper(struct String str) 26: { 27: struct String result; 28: 29: const char *src = str.s; 30: char *dst = result.s; 31: 32: while (*src != '\0') { 33: *dst++ = toupper(*src++); 34: } 35: 36: return result; 37: }まず、注目してほしいのは、このプログラムでは関数での値の受け渡しにポインタを使用していないところです。Cでは構造体は、配列とは違って値渡しが可能です。(同じ型の構造体の変数同士であれば代入が可能)
ですから、このプログラム例では、ローカル変数として定義したString構造体を関数の返り値としていますが、これは前回の記事にあったような「既に消滅したものへのポインタ」ではありません。
関数が処理を終了し、値を返した後(17行目の後)は、関数内で定義したローカル変数であるresult(27行目)は既に消滅していますが、関数はresultが持っていた値をそのまま(コピーして)返したため、関数の結果を受けたstr2の中には、resultにあったのと同じ値が入っています。
もちろん、関数の呼び出しの部分においても、str1の保持している値がそのまま関数に(コピーして)渡されますから(17行目)、関数の仮引数(呼び出しの際に引数として渡された値を格納している変数)には、str1の値がそのまま(コピーして)格納されているわけです。
簡単に言うと、このプログラムでは、struct Stringという構造体に格納された値が、
- 関数に渡され、
- 関数内で別の変数に(変換しながら)渡され、
- 関数の呼び出し元に返され(渡され)る
というステップを経ており、この値のやり取りはすべてコピー(値渡し)で行われているわけです。今回の変数の値、つまりstruct Stringのサイズは4096バイトですので、この4096バイトのデータが関数の呼び出しに絡んで都合3回コピーされることになるのです。
では、ポインタだとどうなるでしょうか? ポインタの場合は、そもそも関数から内部データのポインタを返すことはできないので、一概に比較することはできませんが、ポインタを利用して受け渡すと、コピーされるデータの量は格段に少なくて済みます。ポインタは指しているものの型が何であるかに関係なく、一律にサイズは8バイト(64bitの場合)か4バイト(32bitの場合)になりますので。
このように、配列をそのまま値渡しする仕様だと、メモリーの使用量的にも処理速度面でも、特に配列のサイズが大きい場合、その負担は無視できないレベルになります。しかし、単に先頭要素を指すポインタだけを受け渡すようにすれば、速度的にもメモリーの使用量的にもずっと効率的になります。
そんなわけで、C言語は関数への配列の受け渡しにこのような方法を取っているのだと思われます。
ところで、今まで配列と言っても主に文字列を主体に扱ってきました。しかし、文字列はあくまで「配列の利用方法の1つ」に過ぎません。つまり、「必ず末尾が0(=ヌル文字)になっている」ことを前提にした上での話です。これは、Cにおいては「決まり」というよりは「暗黙の約束事」的な位置付けのことなので、その辺の理解の浅いプログラマがこの約束事を無視したコードを書いても、コンパイラはそれをコンパイルすることを拒否しません。
また、Cでは
- charの配列
- 文字列
- charへのポインタ
を表記の仕方で区別することができないため、そこら辺を「分かっていない」人がコードを書くと途端におかしな動作を呼び起こすことになります。例えば、以下のようなケースを考えてみましょう。
01: #include <stdio.h> 02: #include <string.h> 03: 04: int main(void) 05: { 06: char a = 'A'; 07: 08: printf("length: %ld\n", strlen(a)); 09: 10: return 0; 11: }はっきり言って、おかしなプログラムです。それにまともにビルドもできません(警告は出るけど、とりあえずコンパイルはできてしまう)。
あくまで極端な例ですが、仮に初心者の人がこのようなコードを書いたとします。まあ、こんなコードを書くこと自体「Cが分かっていない」のは明らかですが、それは置いておいて、この人は「とりあえず、長さが1の文字列を作って、それの長さを出力したかった」わけです。
文字列なのに配列を使っていない時点でかなり痛い感じですが(笑)、初めは誰でも(?)こんなものです。
で、コンパイルをしようとしたら警告が出た。メッセージを読むと、どうやらstrlenという関数に渡しているパラメータの型が合っていないらしい。リファレンスを見ると、「charのポインタを渡せ」と書いてある。ってことは、アドレスを渡せばいいんだな…。
てな具合でコードを以下のように修正しちゃいました。
01: #include <stdio.h> 02: #include <string.h> 03: 04: int main(void) 05: { 06: char a = 'A'; 07: 08: printf("length: %ld\n", strlen(&a)); 09: 10: return 0; 11: }これで、無事警告も出なくなって、プログラムは実行可能になりました。早速走らせると、結果は5。「あれ? 何で1じゃないんだろう…」
という感じに話は進んでいくわけです(笑)。
まあ、かなり極端な形で示したのでこれは多くの人は何がまずいのかに気付くでしょう。でも、状況がもう少し混みいって入ると、これに似たようなミスを犯す人は少なくないようです。
Cでは言語の設計的に配列をポインタとして扱うことが多い(特に関数に渡す場合など)わけですが、だからと言って、ポインタはすべて配列だとは限らないわけです。この辺の「なぜ、配列は関数に渡されるとポインタに置き換わるのか」が分かっていないと、上に上げたような間違った関数の呼び方をしてしまう可能性があるので、ここはしっかりと理解しておきたいところです。
ところで、構造体を関数に渡すと値がすべてコピーされることになるわけですが、いくら構造体は配列のようには大きさが増える可能性はないとは言え、ちょっと嬉しくないですよね。
まあ、ご存知とは思いますが、構造体を関数に渡す場合、構造体自体を渡すのではなく、ポインタで渡すことは多いです。もっとも、構造体の中身がさほど多くなく、値渡しのコストがそれほど深刻でない場合は、ポインタではなく値渡しにしてしまうこともあります。例えば、Cocoaでよく使われるNSRect、NSSize、NSRangeなどの型は構造体ですが、これらは値渡しで運用されています。
もちろん、皆さんが設計するメソッドでポインタ渡しにすることは可能ですが、Appleの標準フレームワークでは、ほとんどが値渡しです。ポインタ渡しにしているケースでは、「値の受け取り」の役割として渡しているケースが多いようですね。
-
第215回 関数と配列とポインタの関係〔前編〕 〜ポインタは、なぜ難しいのか?〜
この記事は、2013年01月31日に掲載されました。2013年第一弾の今回(と次回)は、いつもの話をお休みしてちょっと別の話題について考えてみます。
今回のテーマはポインタです。ポインタに関してはこの連載でも何度も取り上げてきました。なので、今さら「ポインタは難しいのか、簡単なのか」について議論する気はありません。今回は、ポインタがよく使われる局面の中でも最も頻度の高いと思われる「文字列とポインタの関係」について考えます。この場合、関数との関係も抜きにすることはできないので、主題は「関数と配列とポインタの関係」としました。
記憶力の良い方は、「あれ、このテーマ前にもやったのでは?」と思われるかもしれません。私自身すっかり忘れていましたが(笑)、この連載の第202回目でも
第202回 改めてCに挑戦!(21) 〜配列・7〜【文字列と配列について】というタイトルで記事を書いていますし、第182回からは「改めてCに挑戦!」というタイトルでCについての解説を綴っていますので、興味のある方はこちらも併せてご覧ください。
まあ、この手のテーマは一通りの解説を読んだだけで理解できることはまれで、多くの人は何度も似たような解説を読み、実際に自分で試して、失敗し…という過程を経ることでようやく理解に至るのです。
ですので、今回はまた少し違った角度から解説を加えることで、皆さんの頭に「ちょっと異なる風」を吹き込んでみようというわけです。さて、文字列を含む配列は、時にポインタと「同一視」されることがあります。これからお話しする特定の状況において、配列はポインタと同一視どころか、まさにポインタそのものに姿を変えてしまうこともあるために、初学者のみならず、ある程度仕事でCやObjective-Cのコードを書いている人ですら、ちゃんと理解出来ていない場合もあるようです。
しかしながら、配列とポインタは同じではありません。
今回は、その辺についてのお話を連ねていき、まだご自分の理解が不充分だと感じておいでの方には、その辺を明確にしていただければと思います。では、以下のようなテーマで簡単なプログラムを作ることを考えてみましょう。
【テーマ】 任意の文字列(英文)のうち、アルファベット小文字をすべて大文字に変換するプログラムを作る。というわけで、まずは、以下のようなプログラムを書いてみました。
01: #include <stdio.h> 02: #include <ctype.h> 03: 04: void convert_lowers2uppers(char *string); 05: 06: int main(void) 07: { 08: char string[1048] = "My sister Mary is 11 years old."; 09: 10: printf("Before: %s\n", string); 11: 12: convert_lowers2uppers(string); 13: 14: printf("After: %s\n", string); 15: 16: return 0; 17: } 18: 19: void convert_lowers2uppers(char *string) 20: { 21: while (*string != '\0') { 22: *string = toupper(*string); 23: 24: ++string; 25: } 26: }出力結果は、以下の通りです。
Before: My sister Mary is 11 years old. After: MY SISTER MARY IS 11 YEARS OLD.ちゃんと目論み通りになっていますね。
Cで文字列の変換をする役割の関数を書く場合、インターフェース、つまりデータの受け渡しのパターンにはいくつか考えられます。
今回のプログラムを例に取ると、- void convert_lowers2uppers(char *string);
- void convert_lowers2uppers(const char *string, char *result);
- char *convert_lowers2uppers(const char *string, char *result);
と言った3つのパターンが、比較的よく用いられるやり方でしょう。
それぞれ、どんな使い方をするのか、どのようにデータ(文字列)の受け渡しをするのか見てみましょう。
1番目のパターンは、文字列を引数として渡し(input)、それにそのまま変換後の値を格納する(output)パターンです。つまり、stringという引数が入出力の両方を兼ねます。
2番目のパターンは、stringがinputで、resultがoutputとなるパターンです。実装例を示すと以下のような感じとなります。
01: #include <stdio.h> 02: #include <ctype.h> 03: 04: void convert_lowers2uppers(const char *string, char *result); 05: 06: int main(void) 07: { 08: char string[] = "My sister Mary is 11 years old."; 09: char result[1048]; 10: 11: 12: printf("Before: %s\n", string); 13: 14: convert_lowers2uppers(string, result); 15: 16: printf("After: %s\n", result); 17: 18: return 0; 19: } 20: 21: void convert_lowers2uppers(const char *string, char *result) 22: { 23: while (*string != '\0') { 24: *result++ = toupper(*string++); 25: } 26: }まず、main関数の頭で、変換元の文字列とは別に結果を格納するための文字列を用意しています。これをそうしないで、例えば14行目を
14: convert_lowers2uppers(string, string);としてしまうとまずいです。こういう使い方ができる実装の仕方も可能なのですが、ここは関数の内部を複雑にしないために、対応していません。
そして、3つめのパターン。これは、2番目のパターンとほとんど同じなのですが、変換元の文字列を引数で渡し、変換結果は返し値として受け取るという方式です。
ここ、ちょっと合点が行かない方もおいでかもしれません。
inputは引数で、outputは返し値で、ということならば以下のようでもいいのではないか? って思いがちです。char *convert_lowers2uppers(const char *string);ところが、このやり方は一見良さそうに見えるのですが、実装をしてみると問題があることが分かります。ちょっとやってみます。
01: #include <stdio.h> 02: #include <ctype.h> 03: 04: char *convert_lowers2uppers(const char *string); 05: 06: int main(void) 07: { 08: char string[] = "My sister Mary is 11 years old."; 09: 10: printf("Before: %s\n", string); 11: 12: printf("After: %s\n", convert_lowers2uppers(string)); 13: 14: return 0; 15: } 16: 17: char *convert_lowers2uppers(const char *string) 18: { 19: char buffer[4096]; 20: 21: for (size_t i = 0; string[i] != '\0'; ++i) { 22: buffer[i] = toupper(string[i]); 23: } 24: 25: return buffer; 26: }まあ、走らせるとうまく行く(場合もある)のですが…
今どきのコンパイラは親切ですね。私の試した少し古めの(Xcode 3.1.4用のGCC4.0)でも、ちゃんと警告で「function returns address of local variable」って教えてくれています。
これは、そのままの通りの意味なのですが、簡単に解説すると、
上記の関数で用意されたbufferという変換結果を格納するための変数(charの配列)は、ローカル変数なのです。ローカル変数ってことは、そのスコープが外れたところで消滅するので、関数から返されたポインタが指している値は「既に消滅した配列の先頭を指すポインタ」です。
まあ、ローカル変数が消滅したと言っても、それがあったメモリの場所のデータをまっさらにする、つまり、0を書き込んで消すなんてことは普通はしないので、この部分が再利用されて別の値が書き込まれるまでは、「残骸として」かつてのデータが残っていますから、このようなケースでは大概「うまく行ったように見える」ので、注意が必要です。こんなわけで、変換する関数が結果をポインタで返す仕様の場合、その返しているポインの指している先がちゃんと関数から戻ってきた後も有効な領域なのかどうかをしっかりと意識しておかないといけません。
もしかしたら、「じゃあ、malloc()で動的にメモリを確保してやったら?」と考える方もいらっしゃるかもですね。確かに、有効な方法ではあります。ただ、実用的かというとそれは疑問です。というのも、malloc()で確保したメモリは使い終わったらfree()で解放しなければならないことはご存知ですね? 呼び出した関数の中でメモリの動的確保が行われているかどうかまで気を使わなければならないのは、関数の使い勝手としてはいいとは言い難いです。
もちろん、時には動的メモリを確保することがその関数の目的である場合もありますから、動的に確保したメモリへのポインタを返す関数もアリなのですが、その場合、きちんと関数の仕様として明記しておく必要がありますし、今回のように動的確保をする必然性が余り感じられないケースでそれをやるのは、良いやり方だとは言えません。そんな理由で、結果を格納する配列も、関数から返った後にも有効であることが必要となるのです。そうなると、取れる方法はグローバル変数かstatic変数か、関数よりも広いスコープを持ったローカル変数を使うということになります。
関数の独立性を高めるためには、グローバル変数を使うのは良い方法ではありませんし、static変数を使うのも、特殊な場合を除き余り適切ではないと思います。
となると、ここはやはり先のプログラムで示したように「結果を格納する配列も引数で渡す」方法が一般的だということが言えます。「でも、それだったら2番目のパターンと同じことじゃないの?」と思われるでしょうね。その通りです。3番目のパターンは、単に「使いやすさ」を優先して、結果をポインタで返しているのです。従って、実装としては以下のような感じになります。
01: #include <stdio.h> 02: #include <ctype.h> 03: 04: char *convert_lowers2uppers(const char *string, char *result); 05: 06: int main(void) 07: { 08: char string[] = "My sister Mary is 11 years old."; 09: char result[4096]; 10: 11: printf("Before: %s\n", string); 12: 13: printf("After: %s\n", convert_lowers2uppers(string, result)); 14: 15: return 0; 16: } 17: 18: char *convert_lowers2uppers(const char *string, char *result) 19: { 20: char *ptr = result; 21: while (*string) { 22: *ptr++ = toupper(*string++); 23: } 24: 25: return result; 26: }1つ前の「失敗例」でも行っていますが、こちらの13行目のように変換の関数をインラインで記述できるのが「ポインタを返す仕様にする」点の1つのメリットです。もちろん、インラインで書かずにいったん別のポインタ変数に受けてから利用しても構いません。
さて、文字列を変換する関数の実装例を見てきましたが、今回の主題はこれからです。
上に挙げたコード例のどれにおいても、charの配列として定義した文字列を関数にそのまま渡しています。そして、関数の側ではそれをポインタとして受けています。関数のプロトタイプはポインタを要求しているのに、それとは「異なる型」である配列を渡しているのに、コンパイラはエラーにするどころか警告すら出しません。
これは何故なのでしょうか?ここには、Cの仕様が深く関わっています。
この連載の第186回目あたりで何度も強調している「Cでは関数の引数は常に値渡し」ということ。さらに言えば、「Cには参照渡しという方法がない」のです。ポインタを使う場合、何らかのデータへの参照として利用することが多いので、そういう意味ではCにも「参照渡しという概念はある」と言ってもいいかもしれません。
言ってることが矛盾していると感じられるかもしれませんが、「参照渡しの概念はあるが、参照渡しの方法はない」ととらえた方が、学習の観点からは都合がいいのです。私の考えでは、ポインタが参照だと思うところにもポインタを難しいと思う一因があるのです。
この連載の以前にも示したように、ポインタは単純な整数値を保持する変数で、それがintやlongなどの整数型と違うのはその値がメモリ上のアドレス値である、ということです。ただ、アドレス値を単純に示しただけだと、
- 果たしてそこから何バイトが対象なのか
- そのメモリ上にあるデータはどんな型なのか
が分からないので、指している先の型が何なのかも併せ持っています。
ちょっと横道に外れますが、以下のプログラムをご覧ください。01: #include <stdio.h> 02: 03: int main(void) 04: { 05: long long value = 8230610272556705096; 06: 07: printf("%s\n", &value); 08: 09: return 0; 10: }何だか、よく分からないプログラムですね。long longの変数をprintf()に渡し、しかも%sで出力しているという…。
実際に動かしてみれば分かりますが(たぶんintel 64bitでも問題なく動くはずですが、intel 32bit環境では確認済み)、何と出力結果は、
Helloと出ます。これを見てすぐに理由が分かる人はかなりポインタを理解できている人ということができるでしょう。
種明かしをすると、上記のvalueという変数に入っている値、8230610272556705096は、16進数で表記すると0x7239006f6c6c6548です。さらに、インテルマシンではバイト並びが逆になるという仕組み(リトルエンディアン)なので、メモリ上のデータは、
48 65 6c 6c 6f 00 39 72 (16進ダンプ)となります。valueというlong longの変数は、メモリ上では8バイトを占め、その中身はこのようになっているということです。さて、ここでピンと来るでしょうか?
先頭からバイトの値をASCIIで表してみると、
48: H 65: e 6c: l 6c: l 6f: o 00: <ヌル文字> 39: 9 72: rもう、分かりましたね? つまりこれは、
char s[] = { 'H', 'e', 'l', 'l', 'o', '\0', '9', 'r' };とした時に配列sが占めるメモリ上の値と「全く同じ」です。
6番目の要素にヌル文字を示す’\0′があるので、それ以降の’9′と’r'は文字列として解釈された時にはないのも同じですから、char s[] = "Hello";と書いたことと(文字列としては)実質同じになるわけです。
printf()という関数は、実は結構危険な関数で、使い方をしくじるとすぐにプログラムを異常終了させる原因になります。それは、チェックが甘い(というか、Cとしてはトリッキーな手法なので、そもそもできるチェックに限界がある)ために、今回のようなテクニック(?)をすらっと使えてしまったりもするのです。つまり、printf()の%sは、対象となる引数が文字列のポインタであると解釈するので、ポインタの示すアドレスから値を順に読み出し、文字コードとして表示していき、0つまりヌル文字に当たったらそこでやめる、という動作をします。
ここでのポイントは、コンパイラはエラーも警告も出さないということです。もしかしたら、最新のコンパイラーは鋭く警告をしてくれちゃうのかもしれませんが、その場合は、
07: printf("%s\n", &value);を
07: printf("%s\n", (char *)&value);とすれば、黙るはずです。このようにprintf()の弱点を突くやり方が卑怯だと思うなら(って、何が卑怯なんでしょうね?・笑)、
01: #include <stdio.h> 02: 03: int main(void) 04: { 05: long long value = 8230610272556705096; 06: char *ptr = (char *)&value; 07: 08: printf("%s\n", ptr); 09: 10: return 0; 11: }のようにしてしまえば、誰に恥じることもないプログラムとなります。
まあ、プログラムそのものの内容はかなり恥ずかしいですが(笑)当然、こんなふうにしてもOKです。
01: #include <stdio.h> 02: #include <string.h> 03: 04: int main(void) 05: { 06: long long value = 8230610272556705096; 07: char string[1024]; 08: 09: strcpy(string, (char *)&value); 10: 11: printf("%s\n", string); 12: 13: return 0; 14: }まあ、キャストはコンパイラに対して、「つべこべ言わずに、オレの言う通りに解釈しろ」と強制する強硬手段ですから、コンパイラは素直に従うしかないわけです。
さて、ちょっとおふざけが過ぎたかもしれませんが(笑)、これを通して皆さんに知っていただきたいのは、型というのは、「メモリ上の値をどのように解釈するか」ということでしかなく、どんな型の値でも、「必ずメモリ上に何らかの数値としてしか存在していない」ということです。
つまり、ポインタというのは型という概念を併せ持つことによって、メモリ上の値をどんな型のデータとしてでも振る舞わせることのできるかなり強力なツールなのです。
良く切れる刃物は扱いを間違えると怪我をするのと同様、ポインタも使い方を誤ると途端に自分(プログラマ)に向かって牙を剥いてくる、そんな存在です(擬人化し過ぎ?)横道にそれていたら、ちょっと話が大きくなりすぎてしまいました。次回は今回のお話をまとめると同時に「何と、配列を値渡しできる方法がある!」というスペシャルテクニックを紹介しようと思いますので、お楽しみに!
-
第214回 Objective-Cから始めるプログラミング(11) 〜Objective-CにCの知識は不要?・1〜
この記事は、2012年11月30日に掲載されました。このシリーズでは、「Cの知識を前提としないObjective-C入門」という切り口でお話を進めてきました。
しかし、実際に私が日常的にObjective-Cを使ってプログラミングをしていると、さすがに「Cの知識は不要」とまでは言い切れないということも実感しています。そこで、今回はどういう場面でCの知識が必要となるのか、という点に関して考えてみたいと思います。まず、「Cの知識」とは何でしょうか? Objective-CがC言語をベースにして成り立っている言語だということは以前から申し上げていますが、素のC言語にObjective-Cという上モノを被せることで、「直接的には」使わなくて済むものはいくつかあります。
例えばmalloc()。恐らく、C言語を既に身に着けていた状態からObjective-Cに入ったプログラマならば、Objective-Cのプログラムでも普通にmalloc()を使うことはあるでしょう。ちなみにご存知のない方のために補足しますと、malloc()という関数は動的メモリ確保のための関数です。特定の大きさの(連続した)メモリ領域が必要な場合、このmalloc()に必要なバイト数を与えてやることで、システムがメモリを動的に確保し、その先頭位置を示すアドレス値を返してきます。(確保できなかった場合はNULLポインタ)
それだけなら、まあさほど難しくも面倒なこともないのですが、malloc()を使って確保したメモリは、使い終わったら必ずfree()という関数でシステムに返してやる必要があるのです。これを怠ると、メモリの動的領域を使い切ることによって発生する「メモリリーク」という状態、つまり「メモリ不足」の状態に陥ってしまいます。
また、malloc()を呼んだ後は、必ずメモリ確保が成功したかどうかの確認も必要だったりします。頭の中だけで考えると、「必要な時に呼び出して、終わったら戻せばいいんでしょ?」って、とても簡単なことに思えるかもしれません。ですが、プログラムの構造が複雑化した場合に、これらのメモリ管理は意外と厄介な問題になってくることも少なくないのです。
そんなことがあるため、Objective-Cでは、というかFoundationフレームワークでは自動解放プール(Autorelease Pool)という仕組みを使って、メモリ管理の負担を軽減させたり、さらにはXcode 4から導入されたARCという仕組みによってプログラマからメモリ管理の負担を取り除く試みがなされています。ただ、たとえARCを使える環境だからといってもメモリ管理の負担が皆無になるわけではありません。
Core Foundationのオブジェクトに関しては、依然としてCFRelease()の呼び出しが必要です。
さて、今回は、私が日常的にObjective-Cでプログラムを書いていて、「ここはCの知識が必要かも」と思った例を1つご紹介します。
いきなりCocoaの話になるので、見えない部分が増える方もおいでかもしれませんが、言わんとするところを汲み取っていただければ幸いです。
テーマにクローズアップするために簡単なプログラムを作ってみました。立ち上がると以下のようなウインドウが開きます。

ラベルには「Hello world! This is Objective-C language.」という文字列が入っていますが、ラベルの幅が狭いので文字列が表示し切れていません。左側の「<< Narrow」と書いてあるポタンをクリックすると、表示されている文字の幅が狭まります。このポタンを何度か押した状態が以下です。

このように、ラベル(実装実体はNSTextField)が表示する文字を変更する際、書体とか文字サイズのような単純な属性であればInterface Builderなどで設定することができますが、それらをプログラムから動的に変更したり、今回のように文字の縦横比や変形を行いたい場合には、コードを書く必要があります。今回のプログラムでは、Controller(App Delegate)が2つのアクションを持っていて、それらは以下のようになっています。(textというのは、ラベルを示すアウトレット)
01: #import "Controller.h" 02: 03: @implementation Controller 04: 05: - (IBAction)narrow:(id)sender 06: { 07: NSTextFieldCell *cell = [text cell]; 08: NSFont *cellFont = [cell font]; 09: NSString *fontName = [cellFont fontName]; 10: 11: CGFloat matrix[6]; 12: memmove(matrix, [cellFont matrix], sizeof(matrix)); 13: 14: matrix[0] -= 1.0f; 15: 16: cellFont = [NSFont fontWithName:fontName matrix:matrix]; 17: [cell setFont:cellFont]; 18: } 19: 20: - (IBAction)reset:(id)sender 21: { 22: NSTextFieldCell *cell = [text cell]; 23: NSFont *cellFont = [cell font]; 24: NSString *fontName = [cellFont fontName]; 25: 26: CGFloat matrix[6]; 27: memmove(matrix, [cellFont matrix], sizeof(matrix)); 28: 29: matrix[0] = [cellFont pointSize]; 30: 31: cellFont = [NSFont fontWithName:fontName matrix:matrix]; 32: [cell setFont:cellFont]; 33: } 34: 35: @endラベルの文字幅を縮めるnarrow:メソッドでも、表示を元に戻すreset:メソッドでも同様ですが、どのようにして文字幅を変えているかというと、
- テキストフィールドセルから使用しているフォントを取得
- そのフォントのマトリックス(座標変換行列)を取得
- マトリックスに対して横幅を変更
- 変更したマトリックスを元に、新規にNSFontのインスタンスを生成
- テキストフィールドセルに新たなフォントを再設定
という手順になります。
ここで登場するマトリックスですが、これはMac OS X/iOSにおいて画面描画を行っているQuartzというシステムが持っている座標変換の仕組みで、詳しくは
https://developer.apple.com/library/mac/#documentation/Cocoa/Conceptual/CocoaDrawingGuide/Transforms/Transforms.html#//apple_ref/doc/uid/TP40003290-CH204-BCIDJJBI
辺りを見ていただくと詳しく書いてありますが、Quartzはアドビの開発したPostScriptが元になった技術ですので、PostScriptの解説を読んだ方が分かり易いかもしれません。「PostScript Language Reference Manual」というドキュメント(最新版は第3版)がAdobeのサイトから入手できますが、日本語版もあることはあります。(価格は、9,240円)
http://www.amazon.co.jp/dp/4756138225/
これらの変換では、座標の変換をするために与える情報を3×3の数値で表すので、これを数学で言うところの「行列」を使って表します。

この図の左2行にそれぞれa, b, c, d, tx, tyと名付け(Appleの説明ではm11, m12, m21, m22, tx, ty)、

それをfloat値6つの配列で表します。この部分が、上記のコードでの11: CGFloat matrix[6];という部分になります。ちなみに右の1行は座標変換の際には常に固定の値なの(3Dになると必要になる)で、無視する形になっています。
この6つの値のどの部分をどのように変えると、それがどのような座標変換になるのかについては興味があったら調べてみていただきたいのですが、ここではひとまず最初の要素、つまり行列での左上の要素(Adobeの説明ではa、Appleの説明ではm11)の値が増えれば横幅が広がり、減れば横幅が狭まるという理屈です。
さて、このコードにおいて「最もObjective-Cっぽくない」のは、
12: memmove(matrix, [cellFont matrix], sizeof(matrix));の辺りでしょうか。cellFontから現在の変換状態を取得して、それをmatrixという変数にコピーしています。単にフォントから変換状態を取得するだけなら、
[cellFont matrix];と書けばいいのですが、その値を複製して変更したいので、このように書いています。このような書き方はC言語的にはきわめて日常的ですが、Objective-Cしか知らない方にとっては、少し理解しにくいコードなのではないでしょうか?
実を言うと、Objective-Cの内部実装はほとんどがC言語で書かれていて、頻繁に使われる機能に関してはすべてObjective-Cの「ラッパ」がかぶさっているために簡単に使うことができます。
ですが、今回の例のように「余りやらない」ことをやる場合、Objective-Cのラッパが用意されていなければ、自分でその代わりをしなければならないということです。 -
第213回 Objective-Cから始めるプログラミング(10) 〜型について・6〜 クラス・3
この記事は、2012年09月29日に掲載されました。前回、クラス継承という方法を用いて機能の拡張を行うということについてご紹介しました。今回は、カテゴリという仕組みを使って同様に機能の拡張を実現する方法について解説します。
では、まずはコードをご覧いただきましょう。
001: #import <Foundation/Foundation.h> 002: 003: @interface Person : NSObject 004: { 005: NSString *name1; 006: NSString *name2; 007: int age_number; 008: } 009: 010: - (id)initWithFirstName:(NSString *)firstName lastName:(NSString *)lastName age:(int)age; 011: - (NSString *)firstName; 012: - (NSString *)lastName; 013: - (int)age; 014: 015: @end 016: 017: @interface Person (special) 018: 019: - (NSString *)fullName; 020: 021: @end 022: 023: @implementation Person 024: 025: - (id)initWithFirstName:(NSString *)firstName lastName:(NSString *)lastName age:(int)age 026: { 027: self = [super init]; 028: if (self) { 029: name1 = [firstName copy]; 030: name2 = [lastName copy]; 031: age_number = age; 032: } 033: return self; 034: } 035: 036: - (void)dealloc 037: { 038: [name1 release]; 039: [name2 release]; 040: 041: [super dealloc]; 042: } 043: 044: - (NSString *)firstName 045: { 046: return name1; 047: } 048: 049: - (NSString *)lastName 050: { 051: return name2; 052: } 053: 054: - (int)age 055: { 056: return age_number; 057: } 058: 059: @end 060: 061: @implementation Person (special) 062: 063: - (NSString *)fullName 064: { 065: return [[self firstName] stringByAppendingFormat:@" %@", [self lastName]]; 066: } 067: 068: @end 069: 070: 071: 072: int main(void) 073: { 074: NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init]; 075: 076: // Personオブジェクトを納める配列 077: NSMutableArray *persons = [NSMutableArray arrayWithCapacity:3]; 078: 079: // 1人め追加 080: Person *aPerson = [[Person alloc] initWithFirstName:@"John" lastName:@"Doe" age:32]; 081: [persons addObject:aPerson]; 082: [aPerson release]; 083: 084: // 2人め追加 085: aPerson = [[Person alloc] initWithFirstName:@"Mary" lastName:@"Stuart" age:18]; 086: [persons addObject:aPerson]; 087: [aPerson release]; 088: 089: // 3人め追加 090: aPerson = [[Person alloc] initWithFirstName:@"Bob" lastName:@"Galway" age:52]; 091: [persons addObject:aPerson]; 092: [aPerson release]; 093: 094: // 配列の内容を表示する 095: for (Person *person in persons) { 096: printf("Name: %s, Age: %d\n", [[person fullName] UTF8String], [person age]); 097: } 098: 099: [pool drain]; 100: 101: return 0; 102: }前回の、クラス継承を用いてSpecialPersonというサブクラスを使ったものとの違いはごくわずかなので、注意してコードを見比べてみてください。
クラス継承のものと異なるのは、以下の2個所です。
017: @interface Person (special) 018: 019: - (NSString *)fullName; 020: 021: @end061: @implementation Person (special) 062: 063: - (NSString *)fullName 064: { 065: return [[self firstName] stringByAppendingFormat:@" %@", [self lastName]]; 066: } 067: 068: @endこれが「カテゴリ」と呼ばれるものです。
まず17行の部分ですが、@interface Personで始まっているので、これはクラスの宣言となります。もっとも、Personクラスは既に3行目で宣言されています。違いを比べてみましょう。003: @interface Person : NSObject017: @interface Person (special)クラス宣言の方は、PersonクラスがNSObjectを継承した新たなクラスであるということを宣言しているのに対し、カテゴリの方はPersonのあとに継承元のクラスを書くのではなく、カッコ付きで「special」と記されています。
このspecialというのは、任意に指定することができ(ただし、implementation部と合致させる必要はあります)るので、「どのような用途・意図でクラスの機能を拡張するのか」を表す表現にすればよいでしょう。それから、次にオブジェクトを生成して使用する部分です。
【オブジェクトの生成】
080: Person *aPerson = [[Person alloc] initWithFirstName:@"John" lastName:@"Doe" age:32];【オブジェクトの使用】
096: printf("Name: %s, Age: %d\n", [[person fullName] UTF8String], [person age]);ここでは、特にカテゴリ拡張をしていることは影響していません。オブジェクトの生成部分では、全く何の違いもなく、単にPersonクラスのオブジェクトを生成します。
そして、オブジェクトを使用する際にはPersonクラスのオブジェクトに対して、[aPerson fullName]というメッセージが投げられます。
このメッセージを処理する際、Objective-Cの実行環境は、通常ならばPersonクラスにはfullNameという名のメソッドがないので例外を投げますが、この場合はカテゴリの機能によって拡張されてfullNameというメソッドが追加されているので、そちらを呼び出すというように動作します。
さて、このようにカテゴリという仕組みを使うことによって、既存のクラスに新たな機能を追加することが可能になるということはお分かりいただけたと思います。でも、クラス継承によって可能なことをわざわざカテゴリという方法でも実現できるようになっているのでしょうか?
同じことを実現するのに、複数の方法があるのはかえって混乱するだけですよね?もちろん、カテゴリにはちゃんとクラス継承とは別の存在理由があります。
今度は別の、もっと単純な例を見てください。
01: #import <Foundation/Foundation.h> 02: 03: int main(void) 04: { 05: NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init]; 06: 07: NSString *hello = @"Hello world"; 08: 09: printf("%s\n", [hello UTF8String]); 10: 11: [pool drain]; 12: 13: return 0; 14: }単純にメッセージを出力するプログラムです。
次に、文字列をちょっと加工してみます。01: #import <Foundation/Foundation.h> 02: 03: int main(void) 04: { 05: NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init]; 06: 07: NSString *hello = @"Hello world"; 08: 09: hello = [hello stringByAppendingString:@"!"]; 10: 11: printf("%s\n", [hello UTF8String]); 12: 13: [pool drain]; 14: 15: return 0; 16: }今度は、一行を追加して、
09: hello = [hello stringByAppendingString:@"!"];メッセージの後ろにビックリマークを付加しました。
さらに加工してみます。01: #import <Foundation/Foundation.h> 02: 03: int main(void) 04: { 05: NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init]; 06: 07: NSString *hello = @"Hello world"; 08: 09: hello = [hello stringByAppendingString:@"!"]; 10: hello = [NSString stringWithFormat:@"<%@>", hello]; 11: 12: printf("%s\n", [hello UTF8String]); 13: 14: [pool drain]; 15: 16: return 0; 17: }今度は、メッセージの前後に山カッコを追加しました。
文字列を追加するにあたり、二通りのメソッドを使っていますが、
09: hello = [hello stringByAppendingString:@"!"]; 10: hello = [NSString stringWithFormat:@"<%@>", hello];これは、単にstringByAppendingString:では後ろに追加することしかできないので、このようにしています。ちなみに、どちらの方法を使った場合でも実はNSStringオブジェクトは「新たに」生成されています。
つまり、文字列が追加されるごとにhelloが指しているオブジェクトは別のものになっています。(分かりますか?)では、さらに文字列を加工して
<Hello world!>
を
<-H-e-l-l-o- -w-o-r-l-d-!->
という感じにしたいのですが、どうしましょう?
NSStringの持つメソッドの中で利用できそうなのは先ほどのstringWithFormat:ぐらいなのですが、これだとメッセージの内容が変化した場合に応用がききません。まあ、複数行のコードをちまちま書いて実現することはもちろん可能なのですが、ここは一行ですらっと済ませてみたいと思います。
実は、こういう時にカテゴリが使えます。
「クラス継承を使ってもいいのでは?」と思われるかもしれませんが、そうすると文字列の生成部分も面倒になるし、できれば標準のNSStringをそのまま使いたいので。
なぁーんて理由もまああるのですが、本当はもっと重要な理由があります。NSStringは実は内部的には複数のクラスが複合的に構成されている「クラスクラスタ」という仕組みで作られています。そのためNSStringをサブクラス化することは推奨されていません。
Foundationのリファレンスにも、Subclassing Notes It is possible to subclass NSString (and NSMutableString), but doing so requires providing storage facilities for the string (which is not inherited by subclasses) and implementing two primitive methods. The abstract NSString and NSMutableString classes are the public interface of a class cluster consisting mostly of private, concrete classes that create and return a string object appropriate for a given situation. Making your own concrete subclass of this cluster imposes certain requirements (discussed in “Methods to Override”). Make sure your reasons for subclassing NSString are valid. Instances of your subclass should represent a string and not something else. Thus the only attributes the subclass should have are the length of the character buffer it’s managing and access to individual characters in the buffer. Valid reasons for making a subclass of NSString include providing a different backing store (perhaps for better performance) or implementing some aspect of object behavior differently, such as memory management. If your purpose is to add non-essential attributes or metadata to your subclass of NSString, a better alternative would be object composition (see “Alternatives to Subclassing”). Cocoa already provides an example of this with the NSAttributedString class.と記述されていて、「サブクラスを作ることはできなくはないけど、いろいろ大変だよ」なんてことが書かれています(笑)。
さらに言えば、プログラムというのは得てして常に変化して行くものでして、
既に大量のコードが存在するプログラムで新たなニーズが生まれた際に、それまでのコードでNSStringが使われている部分を全部書き直すのはかなり大変です。
代わりにカテゴリを使うと、少ない手間で大きな効果が得られるのです。
では、早速やってみましょう。01: #import <Foundation/Foundation.h> 02: 03: @interface NSString (decoration) 04: 05: - (NSString *)stringByAddingDecoration; 06: 07: @end 08: 09: @implementation NSString (decoration) 10: 11: - (NSString *)stringByAddingDecoration 12: { 13: NSMutableArray *characters = [NSMutableArray array]; 14: 15: NSUInteger length = [self length]; 16: for (NSUInteger i = 0; i < length; ++i) { 17: [characters addObject:[NSString stringWithFormat:@"%C", [self characterAtIndex:i]]]; 18: } 19: 20: return [characters componentsJoinedByString:@"-"]; 21: } 22: 23: @end 24: 25: 26: int main(void) 27: { 28: NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init]; 29: 30: NSString *hello = @"Hello world"; 31: 32: hello = [hello stringByAppendingString:@"!"]; 33: hello = [NSString stringWithFormat:@"<%@>", hello]; 34: hello = [hello stringByAddingDecoration]; 35: 36: printf("%s\n", [hello UTF8String]); 37: 38: [pool drain]; 39: 40: return 0; 41: }いかがでしょうか?
実戦的な場面で、いろいろと応用の効くテクニックだと思います。 -
第212回 Objective-Cから始めるプログラミング(9) 〜型について・5〜 クラス・2
この記事は、2012年08月31日に掲載されました。かなり間が開いてしまったので忘れてしまった方も多いでしょうが、前回、クラスというものについて紹介しました。
このクラスというのは1つ以上のデータ(インスタンス変数と呼びます)を内部に保持し、カプセル化することができますが、同時に「いくつかの機能」を提供することができます。この機能を「メソッド」と呼ぶことは前回紹介した通りです。
今回は、クラスの仕組みとして特徴的な「クラス継承」ということについてお話しします。
まずは、コードを見てください。
001: #import <Foundation/Foundation.h> 002: 003: @interface Person : NSObject 004: { 005: NSString *name1; 006: NSString *name2; 007: int age_number; 008: } 009: 010: - (id)initWithFirstName:(NSString *)firstName lastName:(NSString *)lastName age:(int)age; 011: - (NSString *)firstName; 012: - (NSString *)lastName; 013: - (int)age; 014: 015: @end 016: 017: @interface SpecialPerson : Person 018: { 019: } 020: 021: - (id)initWithFirstName:(NSString *)firstName lastName:(NSString *)lastName age:(int)age; 022: - (NSString *)fullName; 023: 024: @end 025: 026: @implementation Person 027: 028: - (id)initWithFirstName:(NSString *)firstName lastName:(NSString *)lastName age:(int)age 029: { 030: self = [super init]; 031: if (self) { 032: name1 = [firstName copy]; 033: name2 = [lastName copy]; 034: age_number = age; 035: } 036: return self; 037: } 038: 039: - (void)dealloc 040: { 041: [name1 release]; 042: [name2 release]; 043: 044: [super dealloc]; 045: } 046: 047: - (NSString *)firstName 048: { 049: return name1; 050: } 051: 052: - (NSString *)lastName 053: { 054: return name2; 055: } 056: 057: - (int)age 058: { 059: return age_number; 060: } 061: 062: @end 063: 064: @implementation SpecialPerson 065: 066: - (id)initWithFirstName:(NSString *)firstName lastName:(NSString *)lastName age:(int)age 067: { 068: self = [super initWithFirstName:firstName lastName:lastName age:age]; 069: return self; 070: } 071: 072: - (NSString *)fullName 073: { 074: return [[self firstName] stringByAppendingFormat:@" %@", [self lastName]]; 075: } 076: 077: @end 078: 079: 080: 081: int main(void) 082: { 083: NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init]; 084: 085: // Personオブジェクトを納める配列 086: NSMutableArray *persons = [NSMutableArray arrayWithCapacity:3]; 087: 088: // 1人め追加 089: SpecialPerson *aPerson = [[SpecialPerson alloc] initWithFirstName:@"John" lastName:@"Doe" age:32]; 090: [persons addObject:aPerson]; 091: [aPerson release]; 092: 093: // 2人め追加 094: aPerson = [[SpecialPerson alloc] initWithFirstName:@"Mary" lastName:@"Stuart" age:18]; 095: [persons addObject:aPerson]; 096: [aPerson release]; 097: 098: // 3人め追加 099: aPerson = [[SpecialPerson alloc] initWithFirstName:@"Bob" lastName:@"Galway" age:52]; 100: [persons addObject:aPerson]; 101: [aPerson release]; 102: 103: // 配列の内容を表示する 104: for (SpecialPerson *person in persons) { 105: NSLog(@"Name: %@, Age: %d", [person fullName], [person age]); 106: } 107: 108: [pool drain]; 109: 110: return 0; 111: }今回も、実行結果は全く同じですが、内部的にはいろいろやってて、新たにSpecialPersonというクラスを登場させています。
「スペシャル」などというからどんなに素晴らしいことをするのかと思いきや、単にPersonクラス(のインスタンス)が姓と名を個別に返すことしかできないの対して、このSpecialPersonクラスはフルネームを返すこともできます。
はっきり言って「スペシャルでも何でもない」ですが(笑)、話が単純な方が説明するのには好都合なのです。
で、このSpecialPersonというクラスですが、注目してほしいのはクラスの宣言部、つまり@interfaceの部分です。
Personクラスが、
003: @interface Person : NSObject 004: { 005: NSString *name1; 006: NSString *name2; 007: int age_number; 008: } 009: 010: - (id)initWithFirstName:(NSString *)firstName lastName:(NSString *)lastName age:(int)age; 011: - (NSString *)firstName; 012: - (NSString *)lastName; 013: - (int)age; 014: 015: @endとなっていたのに対し、SpecialPersonの方は以下のようになっています。
017: @interface SpecialPerson : Person 018: { 019: } 020: 021: - (id)initWithFirstName:(NSString *)firstName lastName:(NSString *)lastName age:(int)age; 022: - (NSString *)fullName; 023: 024: @end何が違うか、お分かりですか?
まず、最初の行ですが、Personが
003: @interface Person : NSObjectとなっているのに対し、SpecialPersonは、
017: @interface SpecialPerson : Personとなっています。
注目していただきたいのは、クラス名のあとのコロンの直後です。PersonではNSObjectとなっていますね。対するSpecialPersonではPersonとなっています。
これは、「クラス継承」という仕組みでして、SpecialPersonはPersonクラスから変数やメソッドを引き継いでいることを示します。引き継ぐ、すなわち「継承」です。
ここで、「あれ?」と思われた方もいるかもしれません。「では、PersonクラスもNSObjectを継承しているの?」と。
その通りです。実は、Objective-Cでは新規にクラスを定義する場合、既存のクラスを継承するか、そうでなければNSObjectを継承することになっています。
PersonクラスがNSObjectを継承しているということは、SpecialPersonクラスも間接的にNSObjectを継承していることになります。つまり、すべてのクラスは直接的または間接的にNSObjectを継承していることになるのです。(ここ、また後で触れますので憶えておいてください)
さて、
SpecialPersonクラスの宣言部(@interface部)には、カラの{ }のペアがあり、これは「変数は何もない」ことを意味しますが、それでもPersonから引き継いだname1, name2, age_numberという3つの変数は持つことになります。次にメソッドですが、SpecialPersonでは以下の2つのメソッドが定義されています。
021: - (id)initWithFirstName:(NSString *)firstName lastName:(NSString *)lastName age:(int)age; 022: - (NSString *)fullName;このうち、fullNameというのは新たに加わったものですが、initWithFirstName:lastName:age:というものは、親クラスであるPersonにおいても定義されています。あ、親クラスというのは継承元のクラスのことです。スーパークラスという呼び方をすることもあります。
で、親クラスにもあるメソッドを継承された子クラス(またはサブクラス)でも定義するとどういうことが起きるかというと、基本的には「上書き」となります。つまり、このメソッドを呼び出すようなメッセージをSpecialPersonのインスタンスに対して送ると、SpecialPersonクラスで定義された方のメソッドが呼ばれます。
今「上書き」と言いましたが、正確にはオーバーライド(override)と言います。Objective-Cに限らずオブジェクト指向言語でサブクラスのメソッドが親クラスのメソッドをオーバーライドする時、その元のメソッド、つまりオーバーライドされた側のものは決してなくなってしまうわけではなく、覆い隠されているといった感じが近いです。ですので、この元のメソッドを呼び出す方法はちゃんと存在します。後でこのやり方には触れます。
さて、このようにObjective-Cにおけるクラスという仕組みでは継承という方法を使って、既存のクラスを再利用することができます。
Personクラスを継承して作ったSpecialPersonクラスには、Personクラスから引き継いだ変数とメソッドが備わっています。SpecialPersonのメソッドの実装部では、それを活用しています。
まずは、fullNameというメソッド。以下のようになっています。
072: - (NSString *)fullName 073: { 074: return [[self firstName] stringByAppendingFormat:@" %@", [self lastName]]; 075: }メソッドの中身はたったの一行ですが、ちょっと込み入っているので少し細かく見てみましょう。
まず、[self firstName]という部分ですが、これは自身のfirstNameというメソッドを呼び出しています。これがPersonクラスから継承されているものだということはお分かりですよね?そして、このメソッドが返してきた文字列(NSString)に対して、今度は
stringByAppendingFormat:というメソッドを呼び出しています。このメソッドはNSStringが持っているメソッドの1つで、引数で書式指定した結果の文字列を、元の文字列の末尾に追加して新しい文字列を生成して返すという動きをします。
ここでは、引数部は@” %@”, [self lastName]となっています。これは、1つの空白文字と、lastNameというメソッドが返す文字列をつなげたものとなりますので、結果的にこのメソッドは、
firstName + 空白文字 + lastNameという文字列を(新たに生成して)返すことになります。
次に、initWithFirstName:lastName:age:という初期化用のメソッドですが、
066: - (id)initWithFirstName:(NSString *)firstName lastName:(NSString *)lastName age:(int)age 067: { 068: self = [super initWithFirstName:firstName lastName:lastName age:age]; 069: return self; 070: }ここで、オーバーライドされたPersonクラスのメソッドを呼び出しています。68行目にあるsuperというのがそのためのキーワードで、現在のクラスのスーパークラスすなわち継承元を表します。
さて、fullNameというメソッドを新たに導入することで名前の表示が少しだけ簡素化しましたが、どうせならすべていっぺんに表示してしまっては? ということで、さらにプログラムに修正を加えてみることにします。
001: #import <Foundation/Foundation.h> 002: 003: @interface Person : NSObject 004: { 005: NSString *name1; 006: NSString *name2; 007: int age_number; 008: } 009: 010: - (id)initWithFirstName:(NSString *)firstName lastName:(NSString *)lastName age:(int)age; 011: - (NSString *)firstName; 012: - (NSString *)lastName; 013: - (int)age; 014: 015: @end 016: 017: @interface SpecialPerson : Person 018: { 019: } 020: 021: - (id)initWithFirstName:(NSString *)firstName lastName:(NSString *)lastName age:(int)age; 022: - (NSString *)fullName; 023: - (NSString *)description; 024: 025: @end 026: 027: @implementation Person 028: 029: - (id)initWithFirstName:(NSString *)firstName lastName:(NSString *)lastName age:(int)age 030: { 031: self = [super init]; 032: if (self) { 033: name1 = [firstName copy]; 034: name2 = [lastName copy]; 035: age_number = age; 036: } 037: return self; 038: } 039: 040: - (void)dealloc 041: { 042: [name1 release]; 043: [name2 release]; 044: 045: [super dealloc]; 046: } 047: 048: - (NSString *)firstName 049: { 050: return name1; 051: } 052: 053: - (NSString *)lastName 054: { 055: return name2; 056: } 057: 058: - (int)age 059: { 060: return age_number; 061: } 062: 063: @end 064: 065: @implementation SpecialPerson 066: 067: - (id)initWithFirstName:(NSString *)firstName lastName:(NSString *)lastName age:(int)age 068: { 069: self = [super initWithFirstName:firstName lastName:lastName age:age]; 070: return self; 071: } 072: 073: - (NSString *)fullName 074: { 075: return [[self firstName] stringByAppendingFormat:@" %@", [self lastName]]; 076: } 077: 078: - (NSString *)description 079: { 080: return [NSString stringWithFormat:@"Name: %@, Age: %d", [self fullName], [self age]]; 081: } 082: 083: @end 084: 085: 086: 087: int main(void) 088: { 089: NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init]; 090: 091: // Personオブジェクトを納める配列 092: NSMutableArray *persons = [NSMutableArray arrayWithCapacity:3]; 093: 094: // 1人め追加 095: SpecialPerson *aPerson = [[SpecialPerson alloc] initWithFirstName:@"John" lastName:@"Doe" age:32]; 096: [persons addObject:aPerson]; 097: [aPerson release]; 098: 099: // 2人め追加 100: aPerson = [[SpecialPerson alloc] initWithFirstName:@"Mary" lastName:@"Stuart" age:18]; 101: [persons addObject:aPerson]; 102: [aPerson release]; 103: 104: // 3人め追加 105: aPerson = [[SpecialPerson alloc] initWithFirstName:@"Bob" lastName:@"Galway" age:52]; 106: [persons addObject:aPerson]; 107: [aPerson release]; 108: 109: // 配列の内容を表示する 110: for (SpecialPerson *person in persons) { 111: NSLog(@"%@", person); 112: } 113: 114: [pool drain]; 115: 116: return 0; 117: }変わった個所は、ごくわずかです。
ただ、最初に注目してほしいのは111行目。111: NSLog(@"%@", person);この一行だけで、
...:10b] Name: John Doe, Age: 32のような出力が出るのです。一体どうなっているのでしょうか?
実は、この辺にはFoundationフレームワークの面白さが潜んでいます。
SpecialPersonクラスを修正して、新しくdescriptionというメソッドを追加しているのですが、実はこのメソッドはオーバーライドなのです。でも、Personクラスにはなかったですよね。一体どこから来ているのかというと、NSObjectから来ているのです。先に、すべてのオブジェクトはNSObjectを直接的または間接的に継承していると言いましたが、このdescriptionというメソッドもNSObjectが持っているものをオーバーライドしたものです。
実はこのdescriptionというメソッドはデバッグ用に用意されているもので、任意のオブジェクトに対してこのメッセージを送ると、そのオブジェクトの状態とか中身などをオブジェクトに応じて文字列として返してくれるものです。
今回、その仕組みを応用して、上記のようなシンプルな呼び出しで姓、名、年齢を出力するようにしてみたわけです。
ところで、以前、NSLog()の先頭に付く時刻などの文字列を出さないようにする方法があると言いましたが、ここでそれを紹介しておきましょう。
クラス継承の話は済んだので、元々この程度のプログラムでクラス継承を使うのも大げさな感じもしますからSpecialPersonは使わずに単純にした例で。
001: #import <Foundation/Foundation.h> 002: 003: @interface Person : NSObject 004: { 005: NSString *name1; 006: NSString *name2; 007: int age_number; 008: } 009: 010: - (id)initWithFirstName:(NSString *)firstName lastName:(NSString *)lastName age:(int)age; 011: - (NSString *)firstName; 012: - (NSString *)lastName; 013: - (int)age; 014: 015: - (NSString *)fullName; 016: - (NSString *)description; 017: 018: @end 019: 020: @implementation Person 021: 022: - (id)initWithFirstName:(NSString *)firstName lastName:(NSString *)lastName age:(int)age 023: { 024: self = [super init]; 025: if (self) { 026: name1 = [firstName copy]; 027: name2 = [lastName copy]; 028: age_number = age; 029: } 030: return self; 031: } 032: 033: - (void)dealloc 034: { 035: [name1 release]; 036: [name2 release]; 037: 038: [super dealloc]; 039: } 040: 041: - (NSString *)firstName 042: { 043: return name1; 044: } 045: 046: - (NSString *)lastName 047: { 048: return name2; 049: } 050: 051: - (int)age 052: { 053: return age_number; 054: } 055: 056: - (NSString *)fullName 057: { 058: return [[self firstName] stringByAppendingFormat:@" %@", [self lastName]]; 059: } 060: 061: - (NSString *)description 062: { 063: return [NSString stringWithFormat:@"Name: %@, Age: %d", [self fullName], [self age]]; 064: } 065: 066: @end 067: 068: 069: 070: int main(void) 071: { 072: NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init]; 073: 074: // Personオブジェクトを納める配列 075: NSMutableArray *persons = [NSMutableArray arrayWithCapacity:3]; 076: 077: // 1人め追加 078: Person *aPerson = [[Person alloc] initWithFirstName:@"John" lastName:@"Doe" age:32]; 079: [persons addObject:aPerson]; 080: [aPerson release]; 081: 082: // 2人め追加 083: aPerson = [[Person alloc] initWithFirstName:@"Mary" lastName:@"Stuart" age:18]; 084: [persons addObject:aPerson]; 085: [aPerson release]; 086: 087: // 3人め追加 088: aPerson = [[Person alloc] initWithFirstName:@"Bob" lastName:@"Galway" age:52]; 089: [persons addObject:aPerson]; 090: [aPerson release]; 091: 092: // 配列の内容を表示する 093: for (Person *person in persons) { 094: printf("%s\n", [[person description] UTF8String]); 095: } 096: 097: [pool drain]; 098: 099: return 0; 100: }以前のものと大きく変わるわけではありません。SpecialPersonで実現していた機能を、Personクラスに直接組み込んでしまったことぐらいです。
肝心の出力部分は、以下のようになっています。
094: printf("%s\n", [[person description] UTF8String]);NSLog()を使わずに、printf()という関数を用いています。これはObjective-Cというよりも標準C言語の中に含まれる関数で、Cの関数としては最も有名なもののうちの1つです。
この関数も、NSLog()と同様に、最初の文字列で書式指定して、その中で%の付いた部分に対応する値を2番目以降の引数で指定する仕組みです。ただ、C言語の関数ですので、NSLog()とはいくつかの違いがあります。
- 書式指定をする最初の引数はC文字列
- 先頭に日付時刻等の情報は出ず、末尾に改行も付かない
- %@は使えない
まず書式指定ですが、C言語にはNSStringはありません。従って、文字列は@の付かないものとなります。
次に、日付や時刻が出ないこと。printf()はデバッグ用というわけでもないので、出力書式に与えた意外のものは基本的には出力されません。それから、末尾には改行がつきませんので、自分で改行を補うこと(上記例にある\nというのが改行を出力する指示です)。もし付けなければ、次の出力がそのまま行の末尾につながります。
そして、%@が使えないこと。これもC言語にはNSStringがないからということなので、%@は使えません。その代わりに%sを使って、Cの文字列を指定するのですが、ここで1つ問題があります。
まず、NSLog()で%@を使った場合、NSStringのインスタンスをそのまま使えますが、CにはNSStringがないため、Cの文字列に変換しなければなりません。そのためにはUTF8Stringというメソッドを使います。
それと、printf()では、オブジェクトのdescriptionメソッドを自動で呼ぶ仕組みもありませんから、これも自分で呼ぶ必要があります。そんなわけで、上記のような呼び出し方となるわけです。
-
第211回 Objective-Cから始めるプログラミング(8) 〜型について・4〜 クラス
この記事は、2012年05月31日に掲載されました。今回は、前回のコードを少し改変して、クラスという仕組みを導入します。このクラスという仕組みの導入によって、同じ人に属する情報をひとまとめにすることができるようになります。
よって、前回のコードで姓、名、年齢ごとに別々の配列を使って表現していたものを1つにまとめ、それを配列に納めて複数の人の情報を扱うことができるようになります。では、コードを見てみましょう。
01: #import <Foundation/Foundation.h> 02: 03: @interface Person : NSObject 04: { 05: NSString *name1; 06: NSString *name2; 07: int age_number; 08: } 09: 10: - (id)initWithFirstName:(NSString *)firstName lastName:(NSString *)lastName age:(int)age; 11: - (NSString *)firstName; 12: - (NSString *)lastName; 13: - (int)age; 14: 15: @end 16: 17: @implementation Person 18: 19: - (id)initWithFirstName:(NSString *)firstName lastName:(NSString *)lastName age:(int)age 20: { 21: self = [super init]; 22: if (self) { 23: name1 = [firstName copy]; 24: name2 = [lastName copy]; 25: age_number = age; 26: } 27: return self; 28: } 29: 30: - (void)dealloc 31: { 32: [name1 release]; 33: [name2 release]; 34: 35: [super dealloc]; 36: } 37: 38: - (NSString *)firstName 39: { 40: return name1; 41: } 42: 43: - (NSString *)lastName 44: { 45: return name2; 46: } 47: 48: - (int)age 49: { 50: return age_number; 51: } 52: 53: @end 54: 55: 56: int main(void) 57: { 58: NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init]; 59: 60: // Personオブジェクトを納める配列 61: NSMutableArray *persons = [NSMutableArray arrayWithCapacity:3]; 62: 63: // 1人目追加 64: Person *aPerson = [[Person alloc] initWithFirstName:@"John" lastName:@"Doe" age:32]; 65: [persons addObject:aPerson]; 66: [aPerson release]; 67: 68: // 2人目追加 69: aPerson = [[Person alloc] initWithFirstName:@"Mary" lastName:@"Stuart" age:18]; 70: [persons addObject:aPerson]; 71: [aPerson release]; 72: 73: // 3人目追加 74: aPerson = [[Person alloc] initWithFirstName:@"Bob" lastName:@"Galway" age:52]; 75: [persons addObject:aPerson]; 76: [aPerson release]; 77: 78: // 配列の内容を表示する 79: for (Person *person in persons) { 80: NSLog(@"Name: %@ %@, Age: %d", [person firstName], [person lastName], [person age]); 81: } 82: 83: [pool drain]; 84: 85: return 0; 86: }実行結果は、前回のものと全く同じです。
2012-05-XX XX:XX:XX.XXX Test_Program[1692:10b] Name: John Doe, Age: 32 2012-05-XX XX:XX:XX.XXX Test_Program[1692:10b] Name: Mary Stuart, Age: 18 2012-05-XX XX:XX:XX.XXX Test_Program[1692:10b] Name: Bob Galway, Age: 52コードの中にいくつかコメントを付加してみましたが、今までよりぐっと複雑さが増しましたのでさらに解説していきます。
まず最初にクラスというものが登場しています。
Personというのがここで独自に定義しているクラスの名前です。Objective-Cではクラスの定義ごとにファイルを独立させることが多いのですが、今回はコードの一覧性を高めるためにすべてを1つのファイルに統合して記述してあります。クラスというものに関しては、今までにもNSStringとかNSArrayというものを見てきています。Personクラスも基本的には同じです。ただ、NSStringなどはあらかじめフレームワークによって定義されて提供されているのに対し、ユーザ(プログラマのこと)が独自に新たにクラスを定義して使うことももちろん可能です。
上記のコードでは、実際にPersonクラスを新たに作るところから行っていますが、作り方の部分はちょっと後回しにして、最初に使い方の方を見ていきます。64: Person *aPerson = [[Person alloc] initWithFirstName:@"John" lastName:@"Doe" age:32]; 65: [persons addObject:aPerson]; 66: [aPerson release];上記のコードから抜き出した部分ですが、aPersonという名の変数を用意して、そこにPersonクラスのインスタンスを生成してから格納しています。
インスタンスの生成部分ですが、以下のような形になっています。[[Person alloc] initWithFirstName:@"John" lastName:@"Doe" age:32]これは、Personクラスに対してまず以下のようにallocというメッセージを送っています。
[Person alloc]メッセージに関しては、すぐあとで説明します。
で、続いて[Person alloc]によって返されたモノに対し、今度はinitWithFirstName:lastName:age:というメッセージを送っています。// ...の部分は[Person alloc]によって返されたモノを表す [... initWithFirstName:@"John" lastName:@"Doe" age:32]つまり2段階のメッセージが連続して送られるという書き方になっているのが64行目のこのコードです。
考え方としては、以下のように別々にメッセージが送られていると考えても大差はないのですが、// idというのは、汎用のオブジェクトを示す型 id obj = [Person alloc]; [obj initWithFirstName:@"John" lastName:@"Doe" age:32];このような書き方はせず、1つにまとめた書き方をします。
さて、今触れた「メッセージ」ということについて少し解説します。
Objective-Cでは、この、ブラケットで囲った形式の書き方を「メッセージ式」と呼びます。ブラケットの中に、空白で区切った2つの項目が並んでいて、左側が「レシーバ」、右側が「セレクタ」と呼ばれます。メッセージ式は、メソッドを呼び出すためのものであるのですが、Objectie-Cでは「メソッド呼び出し」という言い方はしません。何故かと言うと、オブジェクトに対してメッセージを送ったからと言って、必ずしもそのままメソッドが呼び出されるとは限らないからです。
実は、ここにObjective-Cの「動的言語」の側面が表れています。動的言語というのは、プログラムが実際に動作している状態で挙動を柔軟に変えることのできる仕組みで、対する概念である「静的言語」のコンパイル時に挙動が決まってしまうのとは対照的です。
面白いことに、Objective-Cは静的言語であるC言語を拡張する形で作られているため、C言語の仕組みもほとんどまるごと内部に含んでいます。そのためObjective-Cのプログラムコードの中には、C言語で書かれた静的言語な側面と、拡張された仕組みで書かれた動的言語な側面が同居した形になっているのです。
C言語部分では、存在しない関数を呼び出すコードを書くと、「そのような関数は知らない」というエラーメッセージが出てそこでコンパイルがストップします。
ところが、Objective-Cのメッセージ式で、何らかのオブジェクトに対してそのオブジェクトが持たないメソッドを呼び出すようなメッセージを投げるコードを書くと「○○というオブジェクトはそのメッセージに反応することはできないかも」という何だか曖昧な警告を出しはするものの、コンパイルはそのまま完了してちゃんと走らせることができるプログラムが生成されるのです。試しに、以下のようなプログラムを書いてみると実際にご自分で確認ができます。
01: #import <Foundation/Foundation.h> 02: 03: int main(void) 04: { 05: NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init]; 06: 07: NSArray *array = [NSArray arrayWithObject:@"Hello"]; 08: 09: NSLog(@"Array size: %d", [array length]); 10: 11: [pool drain]; 12: 13: return 0; 14: }ビルドをしてみると、7行目のところで、「’NSArray’ may not respond to ‘-length’」というようなウォーニング(警告)が出て、「NSArray(クラスのインスタンス)は、lengthっていうインスタンスメソッドには反応しないかもよ?」と、微妙な感じでお知らせしてくれますが(笑)、そのままビルドは完了し、実行することもできちゃいます。
でも、試した方ならお分かりのように、プログラムは何やら怪しげなエラーをコンソールに書き出して、落ちてしまっているような気配ですね。ちなみに、コンソールの出力は以下のような感じです。(各行先頭の日付やらプロセス名やらの部分は省略)
*** -[NSCFArray length]: unrecognized selector sent to instance 0x104d90 *** Terminating app due to uncaught exception 'NSInvalidArgumentException', reason: '*** -[NSCFArray length]: unrecognized selector sent to instance 0x104d90' Stack: ( 2491314155, 2416143931, 2491343338, 2491336684, 2491336882 )最初の行に注目してみてください。この
-[NSCFArray length]: unrecognized selector sent to instance 0x104d90というのは、「認識できないセレクタがxxxのインスタンスに送られました」ということです。で、次の行、
-[NSCFArray length]:Terminating app due to uncaught exception 'NSInvalidArgumentException', reason: '*** -[NSCFArray length]: unrecognized selector sent to instance 0x104d90'は、「補足できない例外によってアプリケーションは中断されています」というような内容です。(後半は、「理由は…」に続いて上記と同様の内容が書かれています)
「例外」とか「補足」とかは、あまりピンと来ないかもしれませんが、要は「処理のできない要求があったために、アプリケーションを中断した」ということです。
このように、Objective-Cにおける動的な処理においては、アプリケーションが実行する際になるまでエラーを検出できないというようなことが起こり得ます。この部分だけを見ると、「何故、そんな回りくどいことをするのだろう。コンパイル時にエラーとして弾いてしまえばいいのに」と思われる方もおいでかもしれませんね。
今回の例では、動的な処理におけるエラーを分かりやすく示すために端的な例を使って説明したのですが、実際のプログラムにおいては、決してこのように明白なエラーになるケースばかりではないのです。むしろ、動的な処理の構造のおかげでプログラムが柔軟になることもあり、そこがObjective-Cを(もちろん良い意味で)特徴付けている部分でもあります。このように、メソッドを直接呼び出すのではなくあえてメッセージという仕組みを使うことでプログラミングに動的な側面を与えているわけですが、この動的言語的な側面のメリットに関しては、また機会を改めてお話ししようと思います。
メッセージの解説が長くなりましたが、オブジェクトの作り方の話に戻ります。
もう一度、同じ部分を抜粋しますが、64: Person *aPerson = [[Person alloc] initWithFirstName:@"John" lastName:@"Doe" age:32]; 65: [persons addObject:aPerson]; 66: [aPerson release];64行目で作成したオブジェクトを、65行目で「配列に追加」します。そして次の行でreleaseメッセージを送っています。
ここはちょっと難しいところです。話を進めつつ説明しますので、慎重に読み進めてください。
上で抜粋した直後の部分はこのようになっています。69: aPerson = [[Person alloc] initWithFirstName:@"Mary" lastName:@"Stuart" age:18]; 70: [persons addObject:aPerson]; 71: [aPerson release];2人目のデータを表すPersonクラスのインスタンスを生成して配列に追加している部分ですが、ここで1人目の時と違うのはaPersonという変数を使い回しているということです。これはどういうことでしょうか?
一般に、プログラミングの入門書などでは変数というのは「データの入れ物」などと説明されることが多いと思います。実際、この連載でもそのような表現をしたことはあります。
以下のような例、01: int main(void) 02: { 03: int a = 10; 04: 05: printf("a: %d\n", a); 06: 07: a = 5; 08: 09: printf("a: %d\n", a); 10: 11: return 0; 12: }3行目で10に初期化されたaという変数は、10という値を納めているので、5行目の出力で使われる際に当然10という値を返します。
7行目では新たに5という値をaに納めていますので、9行目の出力ではaは5という値を返します。では、7行目でaに新たな値を代入する場合、それまで入っていた値はどうなってしまうのでしょう?
ご想像の通り、前の値である10は消えてしまいます。別の言い方をするなら「元の値は新しい値で上書きされてしまう」となります。
では、オブジェクトの場合はどうなのでしょう? aPersonという変数に入っていた1人目の情報を示すオブジェクトは、64行目で2人目のデータを示すオブジェクトで上書きされて消えてしまうのでしょうか?
実は、ここがオブジェクトとの一般的なデータ型との大きな違いの1つです。
オブジェクトを変数に代入する場合、それはオブジェクトそのものをまるごと変数の中に格納してしまうわけではありません。そもそも、オブジェクトはクラスごとにサイズが違っており、しかもかなり大きいものですから、たかだか数バイトの変数にまるごと格納するなど不可能な話なのです。考え方としては、オブジェクトに関しては変数はそのオブジェクトの実体を示す名札のようなものだととらえると何となくイメージがつかめるかもしれません。
再々度引用しますが、64: Person *aPerson = [[Person alloc] initWithFirstName:@"John" lastName:@"Doe" age:32]; 65: [persons addObject:aPerson]; 66: [aPerson release];64行目で、Personクラスに対してメッセージを送って生成されたオブジェクトは、その時点で「メモリの中に」存在しています。ですが、そのままだとコードでどうやってそのオブジェクトにアクセスすればいいのかは分かりません。そこで、aPersonという変数を使って名札を付けてやります。
ただ、このaPersonという名札はあくまでも一時的なものです。別の名札に付け替えることもできれば、1つのオブジェクトに対して複数の名札を同時に付けることさえ可能です。さらには、オブジェクトに1つも名札がなくなっても、それが別のオブジェクトに格納されていれば、そっち経由でアクセスすることもできるのです。
それをやっているのがまさに今回のコードです。65行目で、配列にオブジェクトを追加をしていますが、ここでこのオブジェクトは「配列の1番目の要素」という位置に格納されるため、もうaPersonという名札に頼らなくてもアクセスできるようになるのです。
従って、69行目で新たなオブジェクトが作られ名札がそちらに付け替えられても、最初のオブジェクトは(アクセスする手段がなくなって)行方不明になってしまう心配がありません。何となく分かっていただけますでしょうか?
今までObjective-Cにおけるモノには型があり、それには整数型とか浮動小数点数型(実数型)というものやオブジェクト型というものがあるとお話ししてきましたが、整数型や浮動小数点数型などのように変数にデータをまるごと納めるものに対して、オブジェクト型では変数の使い方が違っているのだということを認識してみてください。あと、1つだけ補足しておきます。
オブジェクトを生成して配列に追加した後、releaseというメッセージを送っているところがあります。(66行目など)
これは、Foundationフレームワークがオブジェクトのメモリ管理をするために行っている「参照カウント方式」のために必要なのです。メモリ管理に関してはちょっとまた別の話題になりますので今回は端折ってしまいますが、1つだけ勘違いしないでほしいのは、「aPersonという変数に別のオブジェクトを結び付けるため、前に結びついていたものとの関連を切る」などということをしているわけではない、ということを認識しててください。さて、
クラスの使い方の説明を一応終えたので、今度はクラスを新しく定義する方法についてです。今回のプログラムでは、Personというクラスを新しく定義していますが、まず、
@interface Personで始まり、
@endで終わっている部分(3行目から15行目まで)がクラスの宣言部です。通常はこの部分を拡張子がhのファイル(ヘッダファイル)に記述します。Personクラスなので、
Person.hという名前になることが多いですが、必ずそのような名にしなければならないわけではありません。
次に、実装部です。これは
@implementation Personで始まり、
@endで終わります。今回のコードでは17行目から53行目までとなります。この実装部は通常、拡張子がmのファイルに記述することが多いです。(ファイル名はPerson.mとなるのが普通ですが、必ずしもその名前である必要がないのはヘッダファイルと同様です)
クラスというのは、よく「ひな形」と言われることがあるように、「オブジェクトを作る元」となります。作られるオブジェクトがどのようなものであるのかをクラスという構造物として定義するわけです。そしてObjective-Cでは、その定義されたクラスに対してメモリ確保のメッセージと初期化のメッセージを送ることで「インスタンス」が作られることになっています。
説明が前後しますが、インスタンスという言葉を説明します。インスタンスという言い方にはまだ馴染みがないかもしれませんが、以前にも登場している
int a;という、int型の変数を1つ定義するケースにおける「a」という変数もインスタンスです。日本語で言えば「実体」です。
ただ、int型のインスタンスとPersonクラスから作ったインスタンスは「種類」が違います。Personクラス(に限らず、何らかのクラス)から作ったインスタンスは、オブジェクト型です。つまり、オブジェクトに対しても、そうでないものに対しても共に「インスタンス」という呼び方は使われるということはおぼえておいてください。
さてPersonクラスですが、このクラスは「人を表す情報」をひとまとめにするのが目的です。そのため、まず内部にデータ領域として3つの変数を持ちます。これを「インスタンス変数」と呼びます。姓、名、そして年齢を保持したいので、文字列用の変数を2つと、整数用の変数を1つ用意しました。
次に、このオブジェクトが保持している情報を引き出すための入り口を用意します。入り口の役割を果たすのは「メソッド」です。このメソッドはPersonクラスから作られたオブジェクトが備える「機能」なので、「インスタンスメソッド」と呼ばれます。
Personクラスに作られた「姓を呼び出すため」のメソッドは、以下のような形をしています。
- (NSString *)firstName;先頭にマイナス記号がありますが、これはこのメソッドがインスタンスメソッドであることを示します。実はObjective-Cにはメソッドにはもう一種類「クラスメソッド」と呼ばれるものもあります。クラスメソッドの場合には先頭がマイナス記号でなくプラス記号になります。
次に、このメソッドの返すデータの方をカッコで囲って書きます。firstNameメソッドでは
(NSString *)となります。アスタリスクがあることに注意してください。
そして、メソッドの名前が続きます。
インスタンスメソッドを実際に呼び出す時には、以下のような「メッセージ式」と呼ばれる書き方をします。(objectという名のインスタンスがあると仮定してください)
[object method:param];ブラケット([ ])で囲み、先頭にオブジェクトをそして後半にメソッド名と(ある場合には)引数を並べます。この書き方は、余り他の言語には見られないユニークな書き方で、CとかJavaなどの言語ではメソッド(もしくは関数)名のあとのカッコの中に、カンマで区切って引数を並べますが、Objective-Cでは引数ごとに空白で区切り、さらに引数1つに対して必ずコロンが1つ先行します。
いくつか例を示します。
[object methodWithNoArgument];これは、引数のないメソッドを呼び出す時に送るメッセージです。
そして、
[object methodWithArgument:arg];これは、引数が1つある形式のメソッドを呼び出すメッセージ式。
で、
[object methodWithArg:arg1 andArg:arg2];引数が2つある場合にはこのようになります。
注意してみると、引数が2つ以上ある場合、引数同士をカンマで区切るのではなく、空白で区切っています。
また、コロンの前に何らかの文字列があります(上記の例では「andArg」とか)が、これは実はなしにすることも可能で、例えば引数が3つのメソッドの場合、以下のような形式にすることも可能です。[object method:arg1 :arg2 :arg3];1つ目の引数(arg1)のあとに空白が1つ入り、コロンに続いて2つ目の引数(arg2)、そして、空白、コロン、3つ目の引数(arg3)といった形になるわけです。
ただ、言語仕様上はこのような「コロンのみの書き方」も全く問題ないわけですが、それだとそれぞれの引数の役割が見ただけでは分からないので、あまりお勧めはしません。
宣言部、Objective-Cではinterface部ですが、ここではメソッドの「型」を記述していると考えてください。
今回は、ソースファイルが1つしかありませんが、ほとんどのObjective-Cで書かれたプログラムは複数のソースファイルから成り立つのが普通です。そのクラスを使用するコードで該当するヘッダファイルを取り込むのです。
例えば、Personクラスを使う場合、Person.hというヘッダファイルにPersonクラスのinterface定義が書かれていますので、それを使用するコードの先頭の方で
#import "Person.h"と書きます。
そうすると、「Personクラスというのはどのようなクラスであるか」が取り込んだ先でも分かるようになりますから、適切なメソッドの呼び出しや、Personクラスのインスタンスの作成ができるようになるのです。 -
第210回 Objective-Cから始めるプログラミング(7) 〜型について・3〜
この記事は、2012年04月30日に掲載されました。今回は、前回のコードをさらに発展させて、複数の人数を扱うようにしてみます。
では、さっそくプログラムのコードです。
01: #import <Foundation/Foundation.h> 02: 03: int main(void) 04: { 05: NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init]; 06: 07: NSArray *firstNames = [NSArray arrayWithObjects:@"John", @"Mary", @"Bob", nil]; 08: 09: NSString *strings[] = { @"Doe", @"Stuart", @"Galway" }; 10: NSArray *lastNames = [NSArray arrayWithObjects:strings count:3]; 11: 12: int ages[] = { 32, 18, 52 }; 13: 14: for (int i = 0; i < 3; ++i) { 15: NSLog(@"Name: %@ %@, Age: %d", [firstNames objectAtIndex:i], [lastNames objectAtIndex:i], ages[i]); 16: } 17: 18: [pool drain]; 19: 20: return 0; 21: }実行してみると、こんな感じになります。
2012-04-XX XX:XX:XX.XXX Test_Program[1692:10b] Name: John Doe, Age: 32 2012-04-XX XX:XX:XX.XXX Test_Program[1692:10b] Name: Mary Stuart, Age: 18 2012-04-XX XX:XX:XX.XXX Test_Program[1692:10b] Name: Bob Galway, Age: 52今回のプログラムは、扱う「人」の数を3人にしてみたのですが、キモは「同じもの」を扱う場合に、「配列」を使っているところです。配列の仕組みを使って、姓(last name)、名(first name)、年齢(age)ごとにそれぞれをまとめてみました。
配列というのは「同じものが複数個、決まった順序で連なっている」もののことですが、Objective-Cでは配列に2種類あります。1つはオブジェクト型の配列で、もう1つはC言語由来の配列です。オブジェクト型はNSArrayと言い、さらに細分化されるのですが今は深く触れません。ちなみに厳密に言うとNSArrayは、Objective-Cが言語として備えているのではなく、Foundationフレームワークが用意している配列の仕組みです。
ところで、何故配列などというものを使うのでしょうか? それは「同種のものをひとまとめにしておくと、扱う時に便利だから」です。
試しに、上記のプログラムを「配列を使わないように」書き換えてみると、以下のようになります。01: #import <Foundation/Foundation.h> 02: 03: int main(void) 04: { 05: NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init]; 06: 07: NSString *firstName0 = @"John"; 08: NSString *firstName1 = @"Mary"; 09: NSString *firstName2 = @"Bob"; 10: 11: NSString *lastName0 = @"Doe"; 12: NSString *lastName1 = @"Stuart"; 13: NSString *lastName2 = @"Galway"; 14: 15: int age0 = 32; 16: int age1 = 18; 17: int age2 = 52; 18: 19: NSLog(@"Name: %@ %@, Age: %d", firstName0, lastName0, age0); 20: NSLog(@"Name: %@ %@, Age: %d", firstName1, lastName1, age1); 21: NSLog(@"Name: %@ %@, Age: %d", firstName2, lastName2, age2); 22: 23: [pool drain]; 24: 25: return 0; 26: }実行結果は、前と全く同じですが、配列を使わずに要素1つ1つに対して変数を用意しているので、扱う数が増えれば、その分、変数をどんどん増やしていかねばなりません。
例えば、年齢を表すageの場合、3人分が必要ならばage0、age1、age2と3つの変数を用意することになります(なぜ0からなのかは後で触れます)が、これが5人分になればage0からage4まで、100人分ならばage0からage99までという具合に、変数の数自体を増やしていかねばなりません。
もし、人数が100人に増えたらこのプログラムがどんなことになってしまうかは簡単に想像できますよね?配列を使えば、3人分だろうが100人分だろうが、1つの配列変数を用意するだけで足りる訳です。「いくつ分必要かな?」といちいち考える必要すらありません。
配列に納まった要素は、順番が固定されていますから「何番目の要素か」を示す数(インデックスとか添字とか呼びます)で、どの要素でも自在に取り出すことができます。
オブジェクト型のNSArrayの場合、以下のような形でインデックスを指定します。[array_var objectAtIndex:3]とやると、array_varという名のオブジェクト型の変数から「4番目の要素」を取り出すことができます。「3て書いてあるのに、何で4番目?」と思うでしょうが、配列では要素は先頭から0、1、2…というように指定していきます。
次に、C言語由来の配列(こっちは言語自体が持っている機能なので「組み込み配列」なんて呼び方もします)では以下のように要素を指定します。builtin_array[3]
これで、同じように4番目の要素を指定したことになります。
組み込み配列に比べると、NSArrayの方は何か大げさな見た目をしていますよね。これは、オブジェクトというのは多くの場合「データと機能」を持っていて、それを利用するためには「メッセージ」というものを送る必要があるのです。
つまり先ほど書いた[array_var objectAtIndex:3]というコードは、array_varというオブジェクトに対してメッセージというものを送っている文なのです。この辺を詳しく説明すると、脇道に反れ過ぎるので興味のある人は私の過去の連載などをご参照ください。
さて、配列を使うことのメリットの一つにforループという仕組みを使えるというものがあります。ループというのは同じ部分を繰り返し実行させるための仕組みのことですが、Objective-Cではループには大きくわけて二種類あります。whileループとforループです。
「繰り返し実行」と言っても、永久に同じ部分を繰り返してしまうと、それは「永久ループ」もしくは「無限ループ」と言って、プログラマが最も恐れるミスのうちの一つになってしまうので(笑)、必ず「条件判断」とセットになることになっています。whileループは、単純に条件が成立する限りループし続けるというループ構造ですが、forループはループの一周期ごとに変化する要素を持つことができます。Objective-Cの場合、forループには二種類の使い方があるのですが、今回はオーソドックスな使い方を利用しています。
なぜオーソドックスなのかというと、こちらの使い方はC言語から引き継いでいるものだからです。もう一つの使い方は、Objective-Cに最近加わったものです。近いうちにご紹介できると思います。さて、それではforループの典型的な使用例をお見せしましょう。
01: #import <Foundation/Foundation.h> 02: 03: int main(void) 04: { 05: for (int a = 0; a < 10; ++a) { 06: NSLog(@"a -> %d", a); 07: } 08: 09: return 0; 10: }実行結果は、
2012-04-XX XX:XX:XX.XXX Test_Program[1692:10b] a -> 0 2012-04-XX XX:XX:XX.XXX Test_Program[1692:10b] a -> 1 2012-04-XX XX:XX:XX.XXX Test_Program[1692:10b] a -> 2 2012-04-XX XX:XX:XX.XXX Test_Program[1692:10b] a -> 3 2012-04-XX XX:XX:XX.XXX Test_Program[1692:10b] a -> 4 2012-04-XX XX:XX:XX.XXX Test_Program[1692:10b] a -> 5 2012-04-XX XX:XX:XX.XXX Test_Program[1692:10b] a -> 6 2012-04-XX XX:XX:XX.XXX Test_Program[1692:10b] a -> 7 2012-04-XX XX:XX:XX.XXX Test_Program[1692:10b] a -> 8 2012-04-XX XX:XX:XX.XXX Test_Program[1692:10b] a -> 9という感じです。NSLogの中を見てみると、aの値を”a -> %d”という書式で表示しているのが分かります。aの値が%dの部分に置き換わって表示されるわけです。
forループは、以下のような構造をしていて、
for (<第1項> ; <第2項> ; <第3項>) { <ループ本体> }セミコロン「;」で区切られたそれぞれが、以下のタイミングで実行されます。
第1項は、このループに入る最初のタイミングで一回だけ実行される部分。
第2項は、ループの本体が実行される前に条件判断される部分。
第3項は、ループ本体が実行された後に実行される部分。
となります。つまり、forループの部分にさしかかると、第1項が実行され、第2項の条件判断が「OK」となれば、ループの本体を実行、そして第3項が実行されます。
以下、第2項→ループ本体→第3項の順に繰り返され、第2項の条件が不成立になると、そこでforループは終わって、先に進むわけです。
上記の例の場合、最初にaというint型の変数を定義して、0で初期化します。aが10より小さければループ本体のNSLog()部分を実行し、aをインクリメントします。再びaが10より小さいかを判断して…と繰り返しますが、aが10になったところで条件判断がNGになるため、ループを終了するという具合です。念のため触れておきますと、インクリメントというのは「増加させる」という意味です。Objective-Cにはインクリメント演算子というものがあって、
++aの「++」がその演算子で、この場合、aに入っている値を「1増やす」という機能です。整数型の変数にしか使えません。詳しい説明は不要だと思いますが、例えばaに3が入ってい場合、
++a;とすれば、aの中身は4になるわけですね。
さて、最初のプログラムの説明に戻ります。
このプログラム例では配列を4つ利用していますが、1つは補助的な使用です。まず最初の配列は、NSArrayの配列でこれはfirst nameつまり姓名の「名」の方を納めています。
07: NSArray *firstNames = [NSArray arrayWithObjects:@"John", @"Mary", @"Bob", nil];まず、firstNamesという名の変数を定義し、同時に初期化しています。初期化の方法は、NSArrayのクラスメソッドarrayWithObjects:を使用し…
なぁーんて説明をしても分からない方が大半かと思いますので、言い方を変えます。
3つの文字列(NSString型)をカンマ区切りで並べて、最後に「ここで終わり」を意味するnilという記号を付けてやります。
こうすると、一気にNSArray型のインスタンス(オブジェクトのこと。「実体」を意味します)が生成されて中に3つの要素が格納されるのです。それをfirstNamesという変数に割り当ててやるわけですね。どうもまだいろんな用語とか言葉の定義とか説明をしていないために説明がかなりぎこちないですが、Objective-Cプログラマ的に今のを普通に表現すると、
3つの文字列で初期化したNSArrayを作り、firstNamesという名前を付けるなんて感じになるでしょうか。まだあまりピンと来ないかもしれませんが、こういう言い方にも慣れていくといいかもしれません。
次に、順序が逆ですが、先に年齢を示すagesの方を説明します。
12: int ages[] = { 32, 18, 52 };以前、単純なint型の変数を定義する時には以下のようにしました。
int a = 10;これで、aという名のint型の変数が定義され、同時に10という値で初期化されるわけですね。
配列になると、変数名の後ろにブラケット(角カッコ)を付けて、その中に要素数を指定することになります。int b[5];これで、bという名前のint型を格納できる配列の変数が定義されます。格納できる要素数(の上限)は5つです。
配列の場合にも、定義と同時に初期化することができます。以下のようにします。int b[5] = { 25, 30, 48 };初期化したい値をカンマ区切りで波カッコで囲むと、先頭の要素から順に割り当てられます。この例では配列のサイズ(要素数)が5なのですが、初期化の値として与えた値は3つしかないので、先頭から順に3つ分割り当てられますが、残りの2つは未初期化のまま残ります。定義と同時に初期化されないint型の変数と同様です。
また、以下のように書くと、配列のサイズの指定を省略できます。
int b[] = { 25, 30, 48 };この場合は、右側の初期化の値が3項目あるので、配列のサイズは3になります。結果的に、以下のように書いたのと全く同一ですが、
int b[3] = { 25, 30, 48 };右側の要素数を変更するたびにいちいちブラケットの中身を変えなくて済むのでラクです。
さて、最後に姓名の「姓」の方を表すlastNamesの方ですが、これはNSArrayの作り方の別のやり方を示すため、あえてfirstNamesとは別の書き方をしています。
09: NSString *strings[] = { @"Doe", @"Stuart", @"Galway" }; 10: NSArray *lastNames = [NSArray arrayWithObjects:strings count:3];まず、補助的にstringsという配列を用意します。これは組み込み配列を使っています。lastNamesというNSArrayを初期化する際に、このstringsという配列を利用して一気にNSArrayを生成するというのがこちらのやり方です。模式的に構造を示すと、
[NSArray arrayWithObjects:<要素を含む組み込み配列> count:<要素数>]といった感じになります。
ところで、「一度組み込み配列を作っているなら、わざわざNSArrayに入れ直す必要なんてないじゃないか、二度手間では?」と思われる方もおいでと思います。
確かに、その部分だけを見るとその通りなんですが、NSArrayに格納することで、いろいろと都合が良くなることも多いのです。今はまだそんなにお見せしていませんが、NSArrayは先ほども触れたように「機能を持つ」ので、NSArrayに納めてやるといろんな活用が見込めます。さて、こんな感じで姓、名、年齢用の配列を利用してやって、あとはforループを使って書き出しの処理をするわけです。
14: for (int i = 0; i < 3; ++i) { 15: NSLog(@"Name: %@ %@, Age: %d", [firstNames objectAtIndex:i], [lastNames objectAtIndex:i], ages[i]); 16: }ループの本体部は3回、iの値が0、1、2と一つずつ増えながら実行されますので、それぞれの姓名と年齢が表示されることになります。
どうでしょうか? 配列を使うことによってコードの記述量が減らせることを理解していただけましたか?
でも、どうせ「一つにまとめる」なら、いっそのこと姓と名と年齢もひとまとめにしてしまった方がもっとラクですよね。そもそも、名前と年齢が別々の変数になっていると扱いが複雑になります。たとえば、Maryさんの姓は何だっけ?とか、
Galwayさんの姓は何だっけ?ということを記述するのにかなり厄介なことになりそうですので。
そんなわけで、次回は同じ人の情報をひとまとめにしてしまう方法を解説します。 -
第209回 Objective-Cから始めるプログラミング(6) 〜型について・2〜
この記事は、2012年04月23日に掲載されました。今回は、以前ご紹介した最初のプログラムを発展させて、いくつかの要素を組み込んでいきます。
では、さっそくプログラムのコードです。
01: #import <Foundation/Foundation.h> 02: 03: int main(void) 04: { 05: NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init]; 06: 07: NSString *firstName = @"John"; 08: NSString *lastName = @"Doe"; 09: int age = 32; 10: 11: NSLog(@"Name: %@ %@, Age: %d", firstName, lastName, age); 12: 13: [pool drain]; 14: 15: return 0; 16: }実行してみると、こんな感じになります。
2012-04-XX XX:XX:XX.XXX NewObjC_Target[6617:10b] Name: John Doe, Age: 32今回のプログラムでのポイントは
11: NSLog(@"Name: %@ %@, Age: %d", firstName, lastName, age);という部分です。前回同様NSLog()という関数を使用してはいますが、今回はこの関数に対して4つの引数を与えて呼び出しをしています。
@"Name: %@ %@, Age: %d" firstName lastName ageの4つです。
最初の3つはNSStringという種類のオブジェクト型、最後は整数型となります。
連載の207回では、@"Hello world!"のことを文字列と言いました。では、
@"Name: %@ %@, Age: %d"は文字列ではないのか? という疑問が出てくると思いますが、これも文字列です。
「え、文字列なの? それともオブジェクト型なの?」と訳の分からない状態になると思いますが、これはどちらも正しいのです。
前回、型の説明を少ししましたが、Objective-Cには大きく分けると「基本型」と「それ以外」になります。「それ以外」って、ずいぶんアバウトな分類なんですが、まあここでそれ以外をすべて解説しちゃうと、複雑すぎて訳が分からなくなってしまいますので、要は「基本型というのとそうでないのがある」と理解しておいてください。
Objective-Cでは文字列は基本型ではなく、一つはObjective-Cの元になっているC言語に由来する「C文字列」、そしてもう一つはオブジェクトとしてのNSString型という二つになります。最初のうちはオブジェクトであるNSString型のものしか使いませんが、そのうちC文字列も使うことにします。
ところで、基本型というものに分類される型にもいくつか種類があって、たとえば前回ご紹介したintやlongやcharなどの「整数型」、floatとかdoubleなどの浮動小数点数型などがあります。すべての型を網羅して厳密に定義するのがこの連載の趣旨ではありませんので、基本型をすべて列挙することはしません。もしご興味のある方は、書籍や参考資料がいくつかありますので調べてみてください。
さて、例えば基本型の中で頻繁に使われると言っていいint型ですが、この型では整数の値を表現することができます。例をいくつか挙げてみます。
0 -25 352これらは、すべてint型として表現できる値です。そして、他のプログラミング言語もそうであるように、Objective-Cにも「変数」という仕組みがあります。Objective-Cでは変数にも型があります。
Objective-Cでは、変数は、使用する前にあらかじめ定義をする(もしくは使用と同時に定義を行う)必要があり、この時に型も一緒に指定します。例えば以下のような感じです。
int a;これは、Objective-Cにおける宣言文(または定義文)と呼ばれるもので、この例では「aという名前のint型の変数を用意する」ということを意味しています。
定義し終わったら、変数は利用することができます。変数の利用とは、即ち値を格納したり取り出したりすることですので、例えばaに50という値を入れたければ、a = 50;とします。もしくは、上でも触れたように変数の定義と同時に値を設定することが可能で、その場合は以下のように書きます。
int a = 50;これでaという変数の中に50という値が保持されますから、aという値を使うとそれは50という値として評価されます。
「評価される」というのは、変数を「使う」際に、あたかもその変数の中に保持されている値そのものと同じに扱われるということです。例を示します。
まず、NSLog(@"The number is: %d", 50);という関数を実行すると、
2012-04-XX XX:XX:XX.XXX Test_Program[6617:10b] The number is: 50とコンソールに出力されます。あとでちゃんと説明しますが、NSLog()の使い方として、第1引数に与えた文字列の中に%で始まる部分があると、そこに順番に第2引数以降の値を当てはめていくのです。
このため、上記の例では第2引数として与えた50という整数が%dの部分に置き換えられて、(文字列の一部として)出力されています。で、50という値を使う代わりにaという変数を使ってみます。もちろん、このaにはあらかじめ50という値が代入されていると考えてください。
NSLog(@"The number is: %d", a);これで、上と同様に
2012-04-XX XX:XX:XX.XXX Test_Program[6617:10b] The number is: 50という出力が得られます。
こんな具合ですから、冒頭に上げたプログラムの11行目、11: NSLog(@"Name: %@ %@, Age: %d", firstName, lastName, age);では、@%@, %@, %dという部分にそれぞれfirstName, lastName, ageという変数の保持する値が当てはめられて、
2012-04-XX XX:XX:XX.XXX NewObjC_Target[6617:10b] Name: John Doe, Age: 32といった出力になるわけです。大切なのは、%と組み合わせる@やdはそれぞれ引数の型に対応させることが必要で、@はオブジェクト型、dは整数型を出力する場合に指定します。ちなみに、これらの定義は、以下のAppleのサイトに網羅されています。(英語の情報です)
ところで、コードの5行目、
05: NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init];という部分と、13行目の
13: [pool drain];という部分ですが、これは「自動解放プール」という仕組みを使用するためのコードです。いつかメモリ管理についてお話しする時に触れることになりますが、この自動解放プールという仕組みを使うことで、「ある程度」メモリ管理をラクにしてくれるようになっています。
「メモリ管理って、何?」と全く意味不明にしか思えない方もいらっしゃるかもしれません。パソコンにメモリがないと動作しないということは分かりますよね? プログラムでデータを処理する場合、すべての情報は必ずメモリ上に置かれます。基本型のデータに関しては、自動解放プールのような「凝った」仕組みは不要(コンパイラがうまくやってくれます)ですが、オブジェクト型の場合には大量のメモリを必要とするため、メモリの管理は多少複雑になるのです。そこで、それを少し軽減されてくれる仕組みの一つとして用意されているのがこの自動解放プールと呼ばれる仕組みです。
ただ、Mac OS X 10.6、iOS 4でXcode 4.2以降を使った場合に使うことのできるARCという新しい機能を使うとさらにコンパイラがメモリ管理の面倒を見てくれるために、この自動解放プールすら不要になります。(それだけプログラマが楽をできるのです)
最終的にARCを使って、楽をするのは大いに結構なことですが、Objective-Cの裏側(?)で、メモリ管理がどのように行われているのかを知ることは無駄ではないと思いますので、いずれその辺についても解説することにしたいと思います。 -
第208回 Objective-Cから始めるプログラミング(5) 〜型について・1〜
この記事は、2012年03月30日に掲載されました。前回までで最初のプログラムである「Hello world!」のObjective-Cバージョンのコードの解説を終わりましたので、今回からはその解説時にも少し触れた「型」ということについてお話をしていきます。
Objective-Cというプログラミング言語では、プログラムのコードの中に出てくるいろいろなものの中で、特定のものは「型」を持ちます。前回までのプログラムを例に取ると、
その中で使われていた型を持つものは以下のものです。int main() NSLog() @"Hello world!" 0一方、型を持たないものは、
void { return } ;となります。
これらは、すべて「シンボル」と呼ばれるもので、Objective-Cにおける「文法的な最小単位」(ちょっと表現が硬いですが)となります。ちなみに、
#import <Foundation/Foundation.h>の部分がどうして入っていないのかを疑問に思われた方もおいででしょう。この部分は#から始まるように、以前にもお話しした「プリプロセッサディレクティブ」という部分になります。
プリプロセッサは、Objective-Cのコンパイラが走る前の「前準備」をするためのプログラムなので、Objective-Cのコンパイラが動作する時点では既に処理を終えてしまっています。実際には、Foundation.hという名の、Objective-Cにおける「ヘッダファイル」と呼ばれるテキストファイルの中身がこの部分と置き換わることになるので、当然コンパイラからはこの#import <Foundation/Foundation.h>が見えることはありません。
さて、上記のうち「型を持つもの」について考えを進めていきます。
その前にひとつお断り。
話がややこしくなるので、型を持つものはint main() NSLog() @"Hello world!" 0と言いましたが、厳密にはintは型を持ちません。
これは、前にお話しした「void」が「何もない」ということを表すのと同じように、「int」というシンボルは、「intという型を表す」ものということになります。さあ、何だかややこしくなってきましたね(笑)。
少し分かりやすく、たとえ話をしましょうか。
皆さんは、果物が好きですか? まあ、嫌いでも構わないのですが(笑)、以下のうち果物はどれでしょうか?1. りんご 2. バナナ 3. ゾウ 4. ミドリムシ 5. スカイツリー 6. 果物 7. みかん 8. 動物 9. パソコン正解は、1、2、7です。
6は、果物ではなく「果物を表す言葉」です。世の中に「果物」という名前の果物は存在しませんよね? だからややこしいけど、果物という言葉そのものは果物ではないのです。同じように、intというのはintという「型を表す言葉(シンボル)」であって、intというシンボルそのものはintという型を持つものではないということです。何となく分かっていただけましたか?
では、残りのものについて見ていきます。
まず、以下の2つは関数です。関数は型を持ちます。ただ、関数の型の表現はちょっと複雑なので今は端折っておきます。(関数の型表現を必要とすることなんて滅多にないですし)
main() NSLog()次は、文字列型。厳密に言うとNSString型の文字列となります。
@"Hello world!"そして、最後のはint型。整数型のうちの1つです。
0いかがでしょうか?
何となく分かったような分からないような感じかもしれませんが、とりあえずモノには型がある
という感じに受け止めておいていただければOKです。
それでは、何で型というものが必要なのでしょうか?
それは、コンピュータというものがすべてを数値としてとらえることしかできないからです。どんなプログラミング言語を使って書いたプログラムも、現在のコンピュータにおいてはすべてが最終的に「マシン語」と呼ばれる「数値だけで出来た命令の連なり」に変換されて実行されます。コンピュータの頭脳ともいうべきCPUは、数値以外のものは何も処理することができないのです。
コンピュータにとってはすべてが数値ですから、数値だけを扱えればいいかというと、人間の頭というものはそこまで数値を扱うことに長けてはいません。例えば文字を扱ったり色を扱ったり音を扱ったりする場合に、それらがすべて数値で表現されていると、「えっと、こっちの158というのは、色を表していてこんな色、それからこの5968はこの画像のこの部分、そしてあの158は、今度は色ではなくて音」なんて具合になりますが、こんなことを何の混乱もなくさらっとやってのけられる人は、もしこの世に存在していたとしても、かなり特殊な技能の持ち主だといえるでしょう。
この私自身も、当然こんなことをできるような人間ではないし、もともと数値とかは余り得意な方ではありませんから、そんなわけの分からないことをやるよりは、たとえ擬似的にであっても、型という概念を使う方を選びます。
ところで、今までObjective-C以外の言語で、例えばPHPとかRubyとかJavaScriptなどをやってきた経験のある方で、そんなに言語そのものに詳しくはない方の場合、「型のない言語もあるのでは?」と思われてるかもしれません。
しかしそれは誤解です。
確かに、多くのスクリプティング言語では「変数を使う時に、明示的に型を指定することをしません」ですが、それらの変数に格納されるデータにはやはり型があり、当然それらの型によって、変数自体の挙動も違ってくるのです。何だか、ちょっと難しい高度な話になってしまいましたが、付いてこれましたでしょうか?
次回は、実際に型を使って、Hello worldのプログラムを少し発展させていきながら解説をしようと思います。 -
第207回 Objective-Cから始めるプログラミング(4) 〜Hello world解説・2<関数>〜
この記事は、2012年03月13日に掲載されました。さて、main関数の中身の続きです。NSLogという関数を呼び出しているというところからです。
NSLogというのはログを出力するために使用する関数です。ログというのはプログラムの動作を記録しておくためのものですが、そのログを出力するという本来の使い方に関してはひとまず置いておいて、とりあえずは「文字列を表示する」という機能に注目していきます。今回のプログラムを実行した結果は、たとえばXcode 4であれば以下のようになります。(第205回の図を再掲)

(クリックで拡大)
何やらたくさんの文字列が表示されていますが、実際にプログラムが出力したのは上の図では太字になっている以下の部分です。
2012-01-31 23:03:18.887 HelloObjective-C[19688:707] Hello world!単に、”Hello world!”という文字列を出したかっただけなのに、頭に実行時の時刻やらプロジェクト名(本当は実行ファイルの名前)やらが付いてしまっていますが、これはNSLogという関数が記録を取るためのものだからです。
そのうち、純粋に文字列だけを表示するやり方も解説しますが、しばらくはこれで我慢しておいてください。
さて、このNSLogという関数ですが、少し特殊な仕組みになっていて、可変の引数を取ることができます。
通常、Objective-Cの関数はあらかじめ決めた引数の数は固定であり、呼び出す時にもきっちり数を合わせる必要があります。もし決めたのと違う数の引数でその関数を呼び出そうとすると、エラーとなりビルドに失敗します。
ですが、NSLog()は例外的に引数の数を変えることができます。ただ、それも一定の規則にのっとったやり方で行うという制限付きなので、もう少し後に説明するまでそのやり方を知るのは待っていてください。で、今回のNSLog()の呼び出しは、
@"Hello world!"という1つの引数を取っています。
この引数は文字列です。文字列というのは複数の文字を並べてあるもののことで、今回のように文や文章を表すために利用できます。Objective-Cでは「文字列」に2種類あります。
1つは、今回の例のように@(アットマーク)で始まりダブルコーテーションで囲まれているものです。これをObjective-CではNSString型と呼び、オブジェクトと呼ばれる種類のものです。
そして、もう1つは@マークが付かず、単にダブルコーテーションで囲まれているものです。例えば以下のようなものです。"Hello world!"こちらはObjective-Cの元になっているC言語由来の文字列なので、一般に「C文字列」と呼ばれます。詳しい違いはいずれ時を改めて行いますが、このC文字列はオブジェクトではありません。
「オブジェクト型」とか「NSString」とか、これらは「型」という概念で、Objective-Cを使う上では重要ですから、常に意識しておく必要があります。型については次回に解説する予定です。
さて、関数の解説に戻りましょう。
NSLogという関数は、今回のプログラム例では@"Hello world!"という文字列の引数を取っています。これをそのまま(ログとして)記録するのがNSLog()の役割ですから、
NSLog(@"Hello world!");という関数の呼び出しにより、先ほどの
2012-01-31 23:03:18.887 HelloObjective-C[19688:707] Hello world!がログとして記録されるわけです。では、その「記録」はどこにされるのかですが、あまり詳しい話をすると、UNIXの話に立ち入ってしまうことになりますので、簡単な確認方法だけ。
まず、「コンソール」というアプリを立ち上げます。(アプリケーションフォルダの中の「ユーティリティ」というフォルダの中にあります)
そして、コンソールアプリの「ファイル」メニューから、「すばやく開く」→「システムログクエリー」(Lionの場合。Snow Leopardでは「データベース検索」、Leopardでは「ログ・データベース・クエリー」です)→「すべてのメッセージ」と選ぶと「すべてのメッセージ」というタイトルのウインドウが開きます。
いちばん下までスクロールすると、先ほどのプログラムの出力した文字列が見つけられるはずです。もしくは、プログラムの名前を右上の検索フィールドに入力します(一部だけでもOKです)と、表示内容が絞り込まれて、プログラムの出力が記録されていることが確認できるでしょう。
今回のプログラムでは、あくまでNSLog()を文字列表示のために使用していますが、本来の使用法としては、プログラムの中に内部的にこの関数を仕込んでおくと、リリース後にユーザーから「うまく動かないんだけど…」などとトラブル報告があった時に、「コンソールに何か出力されてませんか?」と尋ねたり、もしくはユーザーのマシンに直接アクセスできる場合には自分でコンソールアプリを立ち上げてログを調べる、といったようなことができるわけです。
さて、プログラムの最後の部分ですが、
return 0;となっています。(7行目)
これは、この部分でこの関数、つまりmain関数が終わりであることを示します。同時に、関数を呼び出した元に対して「0」という値を返してもいます。main関数は、プログラムの大元(「エントリーポイント」なんて呼び方をすることもあります)ですから、main関数が0という値を返したということは、つまりプログラム自体が0を返したことになります。
プログラムを呼び出しているのはOS側ですので、OSはこのプログラムを呼び出した後、プログラムが終了するまで待っていて、終了したら0を受け取ることになります。Mac OSでは、Finder上でダブルクリックで立ち上げたアプリが返した値は捨ててしまう(つまり、無視する)のですが、ターミナル上で起動したアプリの場合、プログラムが返した値を利用して、次に行う処理を決めることができます。
具体的には、シェルスクリプトと呼ばれる複数のコマンドを連携して動かすための仕組みで、前のコマンド(=プログラム)が処理に成功したか失敗したかによってその後の処理を切り替えるようなことをするためにプログラムの返し値を利用するわけです。
原則として、プログラムの処理が成功した場合は0を、失敗した場合には0以外(多くの場合は1)を返すという暗黙の約束があります。 -
第206回 Objective-Cから始めるプログラミング(3) 〜Hello world解説・1<関数>〜
この記事は、2012年02月23日に掲載されました。前回、Xcodeもしくはgccなどを使用して、Objective-Cのコードをアプリケーションに仕立てるやり方を解説しましたが、実際に試してみられたでしょうか?
繰り返しになりますが、プログラミングの学習では「自分でコードを打って、実際に動かしてみること」が極めて重要です。「面倒だからコピーでいいや」と思われる方もおいででしょうが、そんなことをすると時間の無駄になります。「え? コピーすると時間の無駄? 逆じゃないの?」と思われたかもしれませんね。ですが、逆ではありません。コードをコピーして動かすのは、結局のところそのコードは完全に「他人のもの」です。それを動かしてみてうまく動いたところで、「自分のプログラムを動かした」ことには全くなりません。
例えば、コンビニでお弁当を買ってきて、それを自宅の電子レンジで温めたら、それは自分で料理したことになりますか? なりませんよね。そんなことをいくら繰り返しても料理の腕が上がるどころか、料理の何たるかすらいつまで経っても分かるようにはならないはずです。
例えば、カレーを作る場合、レトルトの材料を買ってきて、ご飯は自分で炊くとか、野菜は自分で用意して、茹でたり炒めたりするとかすることで、少しは料理という感覚が身に付くというものです。最初は他人の作ったレシピのままに意味も分からずに刻んだり茹でたりするだけかもしれませんが、そういう作業を繰り返しているうちに、次第に意味が分かってきて、いつかはそのレシピにアレンジを加えられたり、ついには自分独自のレシピを編み出せたりするようになるかもしれません。
同じ繰り返すにしても、単にレンジで温めるだけの繰り返しとは雲泥の差です。
プログラミングの場合、他人の書いたコードをコピーしてきてビルドするというやり方を繰り返していても、ビルドの名人にはなれるかもしれませんが、コードを書く技術は全く身に付かないと思った方がいいです。
せっかく単純なところからプログラミングの歩みを進めるのですから、今の段階からできるだけ「自分でできることはやってみる」ことによって、単にコピーしてビルドするだけでは得られないいろいろな体験を積み重ねることができるのです。ずっと複雑な段階まで行ってしまってから、「あれ、これってどういう意味?」と思っても、他の要素が複雑に絡み合っている状態ではそれを解明するのは至難の業、結局はまた最初に戻ってやり直すなんてことにもなりかねません。
ですから、限られた時間でプログラミングの技術を身に付けたいと思われるなら、コードも実際に自分の目で見て、手で打ってみて、細かい記号の1つ1つにまで意識が届くようにしましょう。
さて、コードの解説です。短いので同じコードをもう一度お示しします。
01: #import <Foundation/Foundation.h> 02: 03: int main(void) 04: { 05: NSLog(@"Hello world!"); 06: 07: return 0; 08: }コードの解説の前にちょっと確認しておきますが、前回解説したプロジェクトの始め方の手順通りに行った場合、実際にコードを記述するソースファイルの名前は、Xcode 3.xでは「<プロジェクト名>.m」に、Xcode 4では「main.m」となっていると思います。ここで大切なのは、ファイル名の拡張子が「.m」となっているところです。
gccやclangなどのツールは、複数のプログラミング言語に対応できるように作られているため、処理する対象のファイルがどんな言語で記述されているのかの判断をソースファイルの拡張子を元に行います。このため、Objective-Cで書いたプログラムはソースファイルの拡張子が必ず「.m」となっている必要があることに注意してください。さて、コードの解説ですが、最初なので細かいところまで含めてしっかり見ていきます。
今回のプログラムは最初の例ということもあってとてもシンプルなつくりになっています。大きく分けると2つの要素で成り立ちます。
プリプロセッサディレクティブ部 関数部プリプロセッサディレクティブ部というのが1行目で、残りの3〜8行目が関数部となります。まず、プリプロセッサディレクティブ部を見てみましょう。
#import <Foundation/Foundation.h>これは「import(インポート)文」と言い、これが記述してある部分に他のファイルを取り込む命令です。Objective-Cではコンパイルの処理が走る前に「プリプロセッサ」というその名の通り「事前処理を行うプログラム」が処理を行うのですが、このように#から始まるものを「プリプロセッサディレクティブ」と言います。ディレクティブは「指示」という意味なのでこれは「プリプロセッサへの指示」をすることになります。
上記のケースは「Foundationというフレームワークの中にあるFoundation.hというヘッダファイルの中身をこの部分に取り込みなさい」という指示になります。ヘッダファイルというのは、もともとこのような形で取り込まれるために存在しているファイルで、今回は後述するNSLog()というものを使うために取り込みを行っています。次に関数部です。関数というのはObjective-Cで使われる仕組みの1つですが、関数の特徴を簡単にリストアップすると、
値を返す 任意の数の引数を取ることが可能 内部に処理内容をコードで記述する 「どこか」から呼び出されるとなります。
また、関数の構造は以下のようになっています。(引数が3つある関数の場合)<返し値> <関数の名前>(<引数1>, <引数2>, <引数3>) { <実装部> }「<」と「>」で囲っている部分は実際に何かの値やコードの記述が当てはまることになります。抽象的な説明ではピンと来ないと思いますので、ごくシンプルな関数の例をお見せします。
int add(int a, int b) { return a + b; }上の「構造の解説」に当てはめて考えるとこの関数の例では以下のようになります。
返し値:int 関数の名前:add 引数1:a 引数2:bこのようにaddという関数を定義したら、それをどこかから呼び出すことになります。具体的には以下のように呼び出します。
int result; result = add(3, 5);最初の行は変数というものを定義しています。変数については近いうちに機会を改めて説明しますので、今は「値を格納するもの」と思っていてください。
次の行ではaddという関数を、3と5という値を引数に与えて呼び出して、関数から返ってきた値をresultという変数に格納しています。
関数が、引数(「ひきすう」と読みます)を2つ与え、最終的に何らかの値を返す、ということが分かれば、今の段階は大丈夫です。ところで、今の例のように関数を呼び出すコードは「どこにでも書けるわけではない」のです。Objective-Cにおいて関数を呼び出すことのできる場所は、
関数の中 メソッドの中のどちらかです。メソッドというのはもうしばらくしたら解説しますので、今は「そんなものもあるんだな」程度に考えておいてください。
それから、関数を使用する(つまり呼び出すということ)場合には、先んじて関数の宣言をしておく必要があります。
ただし、Objective-Cの世界ではmainという名の関数だけは例外です。ですから、main関数だけは宣言は不要です。今回のプログラム例では、NSLogという名の関数が使われています(5行目)。この関数の宣言は、実はimport文によって取り込まれたFoundation.hという名のファイルに記述されているのですが、この辺の仕組みは少し複雑なのでまた機会を変えて解説します。さて、今「main関数だけは例外」と言いました。実はObjective-Cではすべてのプログラムは必ずmain関数から始まります。そして、main関数が終わると共にプログラムも終了することになります。つまり、考えようによってはmain関数こそがプログラムの本体だとも言え、すべてのコードはmain関数から直接または間接的に呼び出されることになるのです。
main関数の中身を少し細かく見てみましょう。
まず、関数の名前はmain、返し値はint、引数はvoidとなっています。
intというのはObjective-Cにおける型の1つで、「整数型」と呼ばれる型のうちの1つです。引数のvoidですが、これは型ではありません。
先ほど「関数の引数は任意の数を取ることができる」と言いましたが、この「任意」の中には0も含みます。つまり、引数を1つも取らないということも可能なのです。ただ、言語の仕様上、引数がない場合にint main()というようにカッコの中をカラにすることはできず、必ずvoidという識別子を入れる必要があるのです。
ところで、今後皆さんがさまざまなObjective-Cのコードを見る機会があるでしょうが、その時には以下のような記述を目にすることの方が圧倒的に多いと思います。int main(int argc, const char * argv[]) { ...このように2つの引数を取る形のmainも存在します。これは、このプログラムを起動する際にターミナルなどを使う場合、パラメータを伴って呼び出すことができるのですが、このパラメータを受け取るためにはこれらの引数を使うことになるのです。
ですが、この講座ではそのようなケースは当分想定しないので、混乱を防ぐためにも今はmain関数は引数を取らない形式で記述することにします。さて、関数の残りの部分ですが、
開きカッコ(4行目)と閉じカッコ(8行目)に囲まれた部分が関数の実装部となります。
今回の例ではたった2行(空白行は除く)で、NSLogという関数を呼び出す 呼び出し元に値を返すをそれぞれ行っています。
やっていることは極めて単純なので、ほぼどういうことをしているかは見当が付くでしょう。
次回、それを細かく見ていこうと思います。 -
第205回 Objective-Cから始めるプログラミング(2) 〜プロジェクトの始め方〜
この記事は、2012年02月07日に掲載されました。プログラミングを学習する上で、決して外せないことの1つに「自分で実際にコードを書いて動かしてみる」ことが挙げられます。人の説明を読んだり聞いたりして、理解できたと思っても、それでコードが書けるようになることはありません。
実際にコードを自分で書いて動かしてみることによって、それまで気付かなかったこと、見えていなかったことがあることが分かります。プログラミングには実践ということが欠かせないのです。そこで、早速前回紹介した「最初のObjective-C」コードから、実際に自分のマシンで動かして動作を確認するということをやってみましょう。お手元のMacにはXcodeがインストールされていますか? Xcodeについての説明はいろんなところで目にできると思うのでここでは詳細に触れませんが、説明はXcodeが既に起動できる状態になっているという前提で始めさせていただきます。
XcodeというのはApple社が提供している開発ツールですが、これは「統合開発環境」と呼ばれる複数のアプリケーションから成り立つ開発ツール群です。ちなみに、統合開発環境は英語ではIntegrated Development Environmentと言い、よくIDEと略称で呼ばれることがあることも知っておくといいでしょう。
多くのIDEと同様に、Xcodeでも新しくプログラムを書く際に、まずは「プロジェクト」と呼ばれるドキュメントを作成することになります。実際にXcodeでプロジェクトを作ってみて、それをFinderで確認してみると分かりますが、このプロジェクトのドキュメントのファイルと、実際にObjective-Cのコードを書いていくソースファイル(やヘッダファイル)が1つのフォルダ内にまとめられた形で保存されます。
では、実際にXcodeでプロジェクトを作成し、前回紹介したObjective-Cのコードを走らせてみましょう。と言いたいところなのですが、Xcodeは最近大きなバージョンアップがあり、以前までのXcode 3.x系列と今のXcode 4.x系列では大きくやり方が異なります。
理屈が分かってしまえば両者の違いを自分で吸収して応用することも可能かもしれませんが、まだXcodeに慣れていないと、見た目が違うだけでも「どうしていいかさっぱり分からない」という状態に陥ってしまうでしょうから、今回は最初ということもあるのでXcode 3.x系とXcode 4.x系のやり方をそれぞれ説明します。プロジェクトの作り方を説明するのは基本的に今回だけで、以降はコードを示すのみにとどめるつもりですので、ここでしっかりとプロジェクトの作り方について理解しておきましょう。
まずはXcode 3.xの場合です。以下の画面はMac OS X 10.6上のXcode 3.2での実施例ですので、他のバージョンでは微妙に細部が異なる可能性もあります。(大きく異なる部分があるXcode 3.1.4の例も一部含めます)
Xcodeを立ち上げたら、Fileメニューから「新規プロジェクト…」を選択する。
以下の図のように、Mac OS X、Application、Command Line Toolと選び、TypeのポップアップメニューでFoundationを選ぶ。

(クリックで拡大)
Xcode 3.1.xでは、以下のようにMac OS X、Command Line Utility、Foundation Toolと選ぶ。

(クリックで拡大)
Xcode 3.2と3.1では微妙に違いますが、要は「Command Line」と「Foundation」という言葉が入るように候補を探してみてください。
あとは、右下の「選択…」というボタンを押すと、ファイル保存のダイアログが開きますから、プロジェクトに適当な名前(HelloObjectiveCなど)を付けて、プロジェクト(のフォルダが)保存される場所を選んで保存してください。以上がうまく行くと、以下のように新しいプロジェクトが出来、表示された状態になります。

(クリックで拡大)
Xcode 4.xの場合
Fileメニューから、New、New Project…の順に選び、

(クリックで拡大)
Mac OS X、Application、Command Line Toolと選んでいって、右下のNextボタンを押す。

(クリックで拡大)
以下のように各欄に必要な情報を設定する。
・Product Nameにプロジェクトの名前
・Company Identifierについては後述
・TypeのポップアップメニューはFoundationに
・Use Automatic Reference Countingというチェックボックスがある場合、チェックは外したままにしておく
(クリックで拡大)
Company Identifierというところですが、これは今の段階では空欄にしておいても構わないのですが、空欄のままだと先に進めないようになっているようなので適当な文字を入れておきます。(何でもOKというわけでもないので、アルファベット数文字にしておくのが無難)
ちなみに、この部分は作成したアプリケーションを公開することになった場合には意味を持ってきます。あとからも変更可能ですし、今の段階ではあまり気にすることはありません。新しいプロジェクトが作成され、表示されたところ。(部分)

(クリックで拡大)
以上が、Xcodeの各バージョンにおける新規プロジェクトの作り方です。
あとは、コードを書いて実行するだけです。
プロジェクトウインドウの左側のエリアで、「<プロジェクトの名前>.m」と書いてある項目がソースファイルです。(見つからなければ、黄色いフォルダアイコンの左側の三角ボタンをクリックしてみましょう)これを選択して、最初から書かれているテキストを消して、動かしたいプログラムのコードを記述します。
コマンド+Rというショートカットでプログラムのビルドから実行までが一気に行われます。Xcode 4の場合、結果は以下のような感じになります。
(クリックで拡大)
Xcode 4では、実行結果はこの図のようになります。Xcode 3.xの場合、結果を表示するウインドウは別建てですので、もし表示されていない場合は、コマンド+シフト+Rというショートカットで表示させることができますので、試してみてください。(Xcodeの環境設定によって、自動的に結果ウインドウが表示させるようにすることも可能です)
以上で、今後説明していくプログラムのコードを皆さんが実際に動かしてみる方法が分かったと思います。今後はこの辺の説明は省略しますので、もし分からなくなったらここに戻って確認してみてください。
ところで、Xcodeを使わずにObjective-Cのコードを実行する方法も示しておきます。これは、ターミナルを使ったコマンド入力インターフェースに慣れている人向けの説明です。「ターミナルなんて使ったことがない」という方は気にしなくて大丈夫です。
ソースコードは、適当なテキストエディタで入力してください。保存するエンコーディングはUTF-8にしておくのが無難です。改行コードはLF(UNIX)にします。
保存したソースファイルの名前が「hello.m」だとしたら、以下のようにコマンドを入力することで、プログラムの「ビルド」ができます。
> gcc hello.m -framework FoundationMac OS X 10.6まではこの方法でOKです。Mac OS X 10.7の場合、この方法でも行けるのですが、厳密にはMac OS X 10.7ではデフォルトコンパイラはgccからllvmというものに変わっていまして、CやObjective-Cをコンパイルする際にはclangというツールを使います。
そのため、Mac OS X 10.7では以下のようにビルドします。
> clang hello.m -framework Foundationgccやclangでビルドをすると、カレントのディレクトリに「a.out」という実行ファイルが生成されますので、
./a.outと実行すると、プログラムを走らせることができます。
いかがでしたか? 次回は、Objective-Cで書いたHello worldの中身を見ていくことにします。
-
第204回 Objective-Cから始めるプログラミング(1) 〜準備〜
この記事は、2012年01月24日に掲載されました。さて2012年と同時にスタートしたこの新しい「Objective-Cから始めるプログラミング」ですが、まずはプログラミングの歴史上、外しても外すことのできない(笑)お約束であるHello worldからスタートすることといたしましょう。
ご存じない方のために簡単に説明しますと、Objective-Cの直系の先祖であるプログラミング言語のC(「C」1文字だけだと何のことだか分からない時には「C言語」と表現されたりもしますが)をデニス・リッチー氏(昨年末にスティーブ・ジョブズ氏とほぼ時期を同じくして亡くなりました)とプログラミング関係の著作の多いコンピュータ科学者ブライアン・カーニハン氏が紹介するために書いた「The C Programming Language」(邦訳:プログラミング言語 C)で「最初のプログラムの例」として使用したのが「Hello world」と思われます。
それ以後、いくつかのバリエーションは存在するものの、今でも新しい言語の導入の際のプログラム例として使われることが多いということです。
さて、Objective-C流儀で書くとHello worldは以下のような感じになります。
01: #import <Foundation/Foundation.h> 02: 03: int main(void) 04: { 05: NSLog(@"Hello world!"); 06: 07: return 0; 08: }どうでしょうか? そんなに難しくはないですね。ちなみに、Objective-Cで書いたらいきなりウインドウが出て以下のように

って感じで出ると思っていましたか? 残念ですが、ウインドウやアラートを出すというのはObjective-Cの役割ではなく、CocoaというMac OS Xの中核となるフレームワーク(厳密に言うとCocoaの一部を構成するAppKitというフレームワーク)のお仕事です。(iOSの場合にはUIKitというフレームワークの役割となります)
Objective-CはAppKitやUIKitを呼び出すために欠かせないツールとなりますので、Mac OS XやiOSでアプリケーションを作りたいと思うならば、まずはObjective-Cを学びましょう。「将を射んと欲すればまず馬を射よ」です。(違う?笑)
巷のCocoa/iOSの入門書を見ると、いとも簡単にダイアログやウインドウを表示するステップまで到達してしまうものも多く見られると思います。確かにCocoa/iOS用に用意された強力な開発ツールのおかげで容易に実現できてしまいます。ただ、その裏側でどんな仕組みが動いていてそれをきちんと自分でコントロールできなければ、結局は「単にウインドウが出せただけ」で終わってしまうと考えますがいかかでしょうか?
この連載では、プログラムの動く理屈にこだわって解説を進めていこうと思っています。ですから、歩みは遅いですがしっかりとした足取りで進んでいっていただきたいというのが私が読者の皆さんに望んでいることです。
では、次回は上記のコードを実際に動かしてみるためにはどのようにしたらいいのか、そこを解説していきたいと思います。
-
第203回 Objective-Cから始めるプログラミング(0) 〜前口上〜
この記事は、2012年01月17日に掲載されました。さて、2012年もスタートいたしました。新しい年を迎えるに当たりこの連載も内容をリニューアルし、新しいお話を始めたいと思います。
長年日の当たらない存在であったMacプログラミングも今やiOSという派生OSのおかげで世の中の多くの人が使うOSとなりました。それと同時にMac/iOS以外にはとんど使われることのないプログラミング言語であるObjective-Cも今や言語の人気ランキングが世界レベルでも10位以内に余裕で入るという一昔前には思いもよらなかった状況です(笑)。
【2011年12月の統計】
http://www.tiobe.com/index.php/content/paperinfo/tpci/index.htmlさらにこんな記事も出てきました。
【2011年にシェアを最も伸ばしたプログラミング言語はObjective-C】
http://developers.slashdot.jp/story/12/01/16/0222245/2011-年にシェアを最も伸ばしたプログラミング言語は-Objective-Cそんな中、この私に対しても内外的に「いつまでもC入門じゃないだろう…」という無言・有言の圧力が日々強まってきております(苦笑)。私としては「Objective-CはCの上に成り立っている言語なのだし…」とか「ランキング的に見ても圧倒的にCの方が上じゃないか」という抵抗するのですが、そんな言葉も空しく響きがちな今日この頃…
だったら、いっそ「Cの知識を前提としないObjective-Cの解説が成り立つかどうかを試してやろうじゃないか」と奮起いたしまして、手始めにこのモサ伝で展開してみることにしたわけです。
ただ、くれぐれも誤解のないようにお願いしたいのですが、これから始めるのは「Cの知識を前提としないObjective-Cの解説」であって、「Cを抜きにしたObjective-Cの解説」ではないということです。実際にObjective-Cのコードを書かれた経験のある方ならお分かりのように、「Cを抜きにしたObjective-C」ということ自体論理的に矛盾しているわけですから。
従来は「まずはCを理解した上で、改めてObjective-Cの入門を」という切り口で行っていたスタイルを、「Objective-C入門という切り口で一緒にCも解説してしまう」というやり方に切り替えるわけです。具体的な例をあげれば、プログラミング入門でよく見られる「Hello world」、これを
#include <stdio.h> int main(void) { printf("Hello world!\n"); return 0; }というようにCの書き方で書くのではなく、純粋にObjective-Cの流儀で
#import <Foundation/Foundation.h> int main(void) { NSLog(@"Hello world!"); return 0; }と書いてしまうわけです。
講座としては、最終的にObjective-Cで自分のやりたいことが記述できれば成功ですが、どちらかというとObjective-Cと言った時には隠れがちになるポインタや配列などをどう混ぜ合わせていくか、そこがなかなかに難しそうです。
「Objective-CにはNSArrayなどの配列的な機能が盛り込まれているのだから、Cの配列は必要ないのでは?」と考えられる方もおいでかもしれません。ですが、実戦的なMac/iOSのコードを書いていくと、遅かれ早かれ配列やポインタの知識が必要な場面に遭遇します。特にポインタはCを学ぶ過程で「難所」ととらえられがちな部分ですので、これをいかに必要最小限の説明で切り抜けるかは難しいところだろうと思っています。
そんなわけで、早速次回からObjective-C流でHello worldからお話を進めていきたいと思います。果たしてどうなりますことやら…
-
第202回 改めてCに挑戦!(21) 〜配列・7〜【文字列と配列について】
この記事は、2011年12月28日に掲載されました。皆さんこんにちは、高橋真人です。
さて、今回は配列の7回目ですが、「文字列と配列について」というサブタイトルを掲げてみました。実はちょうど年が変わる時期でもありますので、年明けからまた新しいテーマに変更してみようと計画しているため(年明け1回目から変わるかどうかは未定です)、話を一段落させておこうというわけです。
とはいえ、文字列という新しいテーマを出してきて簡単に語り尽くせるものでもないので、そんなに深い話は期待しないでください(笑)。さて、C言語においては文字列という型は存在しません。配列も、厳密に言うと型(ここでいう型は「基本型」=プリミティブタイプ=という意味です)ではありませんが、それなりの言語によるサポートを得ています。
文字列の場合、「charの配列の特殊なもの」と考えるのが言語的な視点からは順当だと思われます。文字列、つまりstringという仕組みに対するサポートは、Cという言語機能そのものではほとんど行われておらず、多くはライブラリによって与えられているものなのです。では、charの配列とCにおける文字列の違いは何かと言えば、文字列の場合は「末尾がヌル文字で記されていること」だけです。これは、逆も正しいというわけでないので厄介なのですが、
- charの配列を文字列として扱う場合には、必ず末尾をヌル文字で終わらせること
という約束事の上に成り立っているのがCの文字列です。ですから、コードの中にいくつかのcharの配列を定義して、「このうち、文字列なのはどれ?」と聞かれても、定義を見ただけでは判断を付けられるものではないのです。
たとえば、char string[] = "Hello world!";と書けば、これは「多くの場合」文字列だと判断して「ほぼ」問題ないと思いますが、
char string[] = "0123456789ABCDEF";と書いた場合、これは0からFまでを連ねた文字列と見なすこともできますが、同時に数値を16進数を表す文字に変換するためのテーブルだと見なすこともできるわけです。
厳密に言えば、ダブルコーテーションで囲うことで、必ず末尾にはヌル文字が付加される仕組みになっており、これがほとんど唯一と言っていい言語による文字列サポート機能なわけですが、char string[] = { '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', 'D', 'E', 'F' };と書くのが面倒だったり、テーブルの構成要素の見やすさが向上するという理由から、あえて末尾にヌル文字が付くことは甘んじて受け入れた上でダブルコーテーション方式の書き方をすることはよくあります。
また、以下のような書き方をする場合、
char string[] = "Hello\0 world!";話は少し複雑になります。これの特殊性は、Helloの直後に\0(ヌル文字)が入っていることです。このようにCでは文字列の中にバックスラッシュを使って特殊文字の表現を記述することができ、\0というのはヌル文字を意味します。
この変数stringを「文字列として見た」場合は、文字列としてはHelloだけですが、「charの配列として見た」場合には、配列の要素すべて(末尾のヌル文字も含め14個)が含まれることになります。以下のようなプログラムでそれを確かめることができます。
01: #include <stdio.h> 02: 03: int main(void) 04: { 05: char string[] = "Hello\0 world!"; 06: 07: printf("%s\n", string); 08: 09: for (int i = 0; i < sizeof(string); ++i) { 10: printf("%c", string[i]); 11: } 12: printf("\n"); 13: 14: return 0; 15: }出力結果は、
Hello Hello world!となります。後の方(forループを使った1文字ごとの出力)では、ヌル文字も出力されていますが、見えない文字なので存在は少し分かりにくいですね。
このプログラムで大切なのは、9行目のループの上限にsizeof演算子を使って「配列の大きさ」を指定しているところです。ここを間違って、09: for (int i = 0; i < strlen(string); ++i) {としてしまうと、上限は14ではなく5となってしまうので、Helloだけしか出力されません。ついでに補足しておきますと、strlen()を使う場合には、コードの冒頭で
#include <string.h>と入れる必要がありますが、このstring.hというヘッダは、まさにcharの配列を文字列として使う場合に有用な仕組みがたくさん詰まっているヘッダです。Cにおいてはstrとかsというキーワードで「文字列として扱う」ことを表明しており、その場合、対象となる文字列はcharへのポインタとして表現されますが、必ずこれは末尾がヌル文字になっているということがお約束であるわけです。
その「お約束」を守らずにコーディングしてしまうと、文字列絡みのトラブルに見回れ、バグの嵐に見舞われることになってしまうわけですね。さて、今回は配列と文字列の違いについて簡単に見てきました。単純なことながらかなり重要なポイントでもあるので、皆さんもそれぞれ確認してみていただければ幸いです。
それでは、よいお年を!
-
第201回 改めてCに挑戦!(20) 〜配列・6〜
この記事は、2011年12月20日に掲載されました。皆さんこんにちは、高橋真人です。
前回ご紹介したmemsetという関数ですが、これはstring.hの中に宣言されています。Mac OS Xのマニュアルを見ると、以下のように出ています。ちなみに、この手の関数の仕様を調べるにはXcodeのヘルプを使うか、ターミナルを立ち上げてman memsetもしくは
man 3 memsetと打ち込みます。
記述が英語である以前にターミナルの操作に慣れないと見方も分からないかもしれませんが、以下の操作だけでも覚えておけばほぼ問題なく使えるでしょう。- space: 1画面分進む
- j: 1行分進む
- b: 1画面分戻る
- k: 1行分戻る
- q: 終了する
- h: ヘルプを表示する
マニュアルのmemsetの項目の先頭は以下のようになっています。

めぼしい項目をいくつか拾ってみます。
NAME: memset -- write a byte to a byte stringこれは、APIの名前と動作の概要が記述されています。
LIBRARY: Standard C Library (libc, -lc)これは、このAPIが属するライブラリの記述です。memset()は、標準Cライブラリに属しています。
SYNOPSIS: #include <string.h> void * memset(void *b, int c, size_t n);synopsisというのは演劇などであらすじを意味する言葉だそうですが、ここでは取り込むべきヘッダと関数のプロトタイプが示されています。恐らく、APIのマニュアル検索をする目的の多くはこの項目を見るためで、まずstring.hというヘッダファイルをインクルードすること(つまり、このヘッダファイルの中にこの関数のプロトタイプ宣言が記述されています)と、関数の使い方、要はどのように呼び出すかの仕様が示されています。
memset()では、引数は順にポインタ、満たすべき値、満たす分量となります。DESCRIPTION: The memset() function writes n bytes of value c (converted to an unsigned char) to the string s.これは、APIの記述ということで、ここでは「memset()関数は、cの値を文字列sに対してnバイト分、書き込む」となっています。
RETURN VALUES: The memset() function returns its first argument.関数の返り値が示されています。memset()では、第1引数に与えられたポインタがそのまま返されます。
以上のように、ライブラリのマニュアルを引くことを覚えると、「あれ、この関数の使い方はどうするんだっけな?」という時に、ちょこっと調べてすぐに答えを得ることができるようになるわけです。
memset()を使う場合には、
#include <string.h>としておき、3つの引数を適切に与えて呼び出すことになります。前回の最後のコード例では、引数はそれぞれarray、0、ARRAY_LENGTH(array)となりますが、この部分だけを簡単なコード例で示してみます。
01: #include <string.h> 02: 03: int main(void) 04: { 05: int array[10]; 06: 07: memset(array, 0, sizeof(array)); 08: 09: return 0; 10: }何の出力もしない、プログラムとしては何の意味もないコードですが、示しているのは配列の初期化です。もっと正確に言うと「配列のすべての要素を0にしている」となります。
ちなみに、前回の例ではARRAY_LENGTHというマクロを使って「配列の要素数」を指定していましたが、本当は今回の例のように「配列のサイズ」(バイト数)を指定する方が正しいです。前回の例では配列の要素がcharなので要素数とバイト数に違いは出てきませんが、配列の要素がchar以外の場合に要素数で指定するとまずいことになります。前回の例は余り良くないですね、すみません。とりあえず簡単な配列の例をご紹介しましたが、配列の要素が構造体の場合どうなるでしょうか。特に、以前お話しした構造体の「隙間」が絡むケースでのこともちょっと気になります。例えば以下のような例。
01: #include <stdio.h> 02: #include <string.h> 03: 04: struct Something { 05: char c; 06: short sh1; 07: short sh2; 08: long l; 09: }; 10: 11: void DumpArray(void *ptr, size_t length); 12: 13: int main(void) 14: { 15: struct Something someArray[2] = { 0 }; 16: 17: DumpArray(someArray, sizeof(someArray)); 18: 19: memset(someArray, 0xff, sizeof(someArray)); 20: 21: DumpArray(someArray, sizeof(someArray)); 22: 23: for (int i = 0; i < 2; ++i) { 24: someArray[i].c = 0; 25: someArray[i].sh1 = 0; 26: someArray[i].sh2 = 0; 27: someArray[i].l = 0; 28: } 29: 30: DumpArray(someArray, sizeof(someArray)); 31: 32: return 0; 33: } 34: 35: void DumpArray(void *ptr, size_t length) 36: { 37: for (size_t i = 0; i < length; ++i) { 38: if (i % 8 == 0) { 39: printf("%02d: ", i); 40: } 41: 42: printf("%02X ", ((unsigned char *)ptr)[i]); 43: 44: if (i % 4 == 3) { 45: printf(" "); 46: } 47: 48: if (i % 8 == 7) { 49: printf("\n"); 50: } 51: } 52: printf("\n"); 53: }実行結果は以下のようになります。
00: 00 00 00 00 4B 15 E0 8F 08: 00 10 00 00 00 00 00 00 16: 00 00 00 00 CC F6 FF BF 00: FF FF FF FF FF FF FF FF 08: FF FF FF FF FF FF FF FF 16: FF FF FF FF FF FF FF FF 00: 00 FF 00 00 00 00 FF FF 08: 00 00 00 00 00 FF 00 00 16: 00 00 FF FF 00 00 00 00Somethingという以前の例でも使用した構造体を2つ要素に持つ配列を作り、それをmemset()などでいじってみたわけですが、DumpArray()という関数を使って配列の内容をダンプして中のデータの状態を確認しています。注目してほしいのは、このDumpArray()という関数はSomethingという構造体のことを知らないので、単に与えられたポインタをバイトの連続とみなして順に16進数で表示していることです。
最初のDumpArray()の呼び出し(17行め)では、配列の要素が初期化されていないため、出力される内容は不定です(こういうのを「ゴミ」と言います)。
2回めのDumpArray()の呼び出し(21行め)では、memset()を使って値の設定を行っていますが、今までの例とは異なり、0ではなく0xffで全要素の設定を行っています。
3回めのDumpArray()の呼び出し(30行め)では、23行めからのforループで配列の各要素である構造体(Something)の各メンバにそれぞれ0を設定した結果を表示しています。この結果から分かるのは、構造体のメンバ個別に値を設定した場合と、memset()を使って値を設定した場合の違いです。DumpArray()が行っているのと同様に、memset()では第1要素をバイト列の先頭と解釈するため、配列の要素が構造体だろうがそんなことはおかまいなく、すべてのバイトに対して値の設定を行うのです。
実際のプログラムにおいて、この構造体の隙間の値が影響を及ぼすことはまずあり得ない(特殊な扱い方をした場合はその限りではない)ので、23行めからのforループでのようなやり方をするのも、memset(someArray, 0, sizeof(someArray));とするのも動作に違いが出ることはありませんが、厳密に同じことをしているわけでないということを知っておくのはムダなことではないと思います。
-
第200回 改めてCに挑戦!(19) 〜配列・5〜
この記事は、2011年11月30日に掲載されました。皆さんこんにちは、高橋真人です。
配列の初期化ということについてお話ししてきました。いろいろと説明をしましたが、簡単に整理すると「初期化」と言う場合、2つの意味を持つことがあって、1つは- 変数の定義と同時に値を設定すること
そしてもう1つは、
- 変数の値を「ゼロ」にしておくこと
です。
後者については少し後で論じますが、前者について少し考えてみます。
まず、変数の定義と同時に初期値を与えることを初期化というわけですが、コードで書くと以下のような感じになります。int a = 100;これによって、変数のaの値は100になるわけです。一方、以下のようなコードもよく見かけると思います。
int a; a = 100;このように書くと、aは一度定義され(値は不定値)、次の段階で100という値が代入されるのだと思うかもしれません。実際、コードはそのように書いてありますから。ですがこの場合、上のように定義と同時に値を設定しているのと実は全く変わりません。コンパイラが「同じ意味」だと解釈して、全く同じコードを生成します。
ちなみに、以下のようなプログラムでも、コンパイラは全く同じ実行コードを生成します。【プログラム例1】
01: #include <stdio.h> 02: 03: int main(void) 04: { 05: int a = 100; 06: int b = 555; 07: 08: printf("a: %d, b: %d\n", a, b); 09: 10: return 0; 11: }【プログラム例2】
01: #include <stdio.h> 02: 03: int main(void) 04: { 05: int a; 06: int b; 07: b = 555; 08: a = 100; 09: 10: printf("a: %d, b: %d\n", a, b); 11: 12: return 0; 13: }後者では、aに値が代入される(8行目)よりも先にbに値が代入されて(7行目)います。ですから、「前者とは初期化順が逆だからコードも違ってくるのでは?」と考えられるかもしれません。確かに理屈はその通りなのですが、この違いは実行結果の違いとして出てくるものではないので、昨今のコンパイラは両者を同じものとして解釈するようです。(*)
さて、あらかじめ値を設定した形で変数を初期化するのに対して、既に定義され、使用されていた変数を初期化する、というケースがあります。この場合、ハードディスクを初期化するとか、SDメモリーカードを初期化するとかと同じように、「今まで入っていたデータを消去する」という意味での初期化ということになります。
もっとも、ハードディスクも最初に使う時に初期化が必要となるケースもありますので、「まっさらな状態にする」ことを初期化と呼ぶと考えてもいいかもしれません。このような場合、Cでは値をゼロにすることになります。Cでは「変数に何も値がない」という状態にはできません。それは、そもそもメモリーというものが0も含めて何らかの値が入った状態でしか存在し得ないということでもあります。
たとえば、charの変数を定義するとします。char c;このように書くと、cという名の変数が定義されますが、その値は「不定」となります。不定というのはどういうことかと言いますと、「どの値になるか分からない。決まっていない」ということです。
間違えてはいけないのは、この場合、値はcharが取りうる「-128から127」の間のどれかに必ずなるということです。char型として表現できる範囲以外の値になることは決してありません。
以下のようなプログラムを実行した場合、01: #include <stdio.h> 02: 03: int main(void) 04: { 05: char c; 06: 07: printf("c: %d\n", c); 08: 09: return 0; 10: }出力結果は「どうなるか分からない」のです。
試しに実行してみましたが、c: -113という結果になりました。大切なのは、この出力結果は「たまたま」だということで、常に-113と出るわけではないということです。
このように、初期化をしていない変数がある場合、その中に格納されている値が何であるかは不明なので、この値をそのまま使うことはありませんし、使うことは(今回のような「わざと」やっている場合を除き)何の意味も持ちません。
こんなわけですから、変数を定義したものの何も値を設定していない状態は「極めて不安定かつ危なっかしい状態である」と言うことができますので、「とりあえずゼロにしておきましょう」というのが(2番目の意味での)初期化というわけです。
単純な値の場合、初期化するにはint a = 0;とすればいいわけですが、変数が配列になっている場合には、連載の194回でお話ししたように、
int array[10] = { 0 };という書き方をします。こうすると、配列の要素の10個すべてが0に設定、つまり初期化されることになります。
ところで、先ほど例に出しましたハードディスクなどの例のように、使用していたものの値をカラ、つまりゼロに初期化するにはどうしたらよいのでしょうか? もちろん、以下のようにオーソドックスに(?)ループを回して改めて0にすることも可能です。(27行目からのinit_array関数)
01: #include <stdio.h> 02: 03: #define ARRAY_LENGTH(ARRAY) (sizeof(ARRAY)/sizeof(ARRAY[0])) 04: 05: void init_array(int array[], size_t length); 06: void print_array(const int array[], size_t length); 07: 08: int main(void) 09: { 10: int array[10] = { 0 }; 11: 12: print_array(array, ARRAY_LENGTH(array)); 13: 14: for (int i = 0; i < ARRAY_LENGTH(array); ++i) { 15: array[i] = i * 10 + 1; 16: } 17: 18: print_array(array, ARRAY_LENGTH(array)); 19: 20: init_array(array, ARRAY_LENGTH(array)); 21: 22: print_array(array, ARRAY_LENGTH(array)); 23: 24: return 0; 25: } 26: 27: void init_array(int array[], size_t length) 28: { 29: for (int i = 0; i < length; ++i) { 30: array[i] = 0; 31: } 32: } 33: 34: void print_array(const int array[], size_t length) 35: { 36: for (int i = 0; i < length; ++i) { 37: printf("[%d]: %d\n", i, array[i]); 38: } 39: printf("\n"); 40: }ですが、こういうケースではCではよく以下のような書き方をされることがあります。
01: #include <stdio.h> 02: #include <string.h> 03: 04: #define ARRAY_LENGTH(ARRAY) (sizeof(ARRAY)/sizeof(ARRAY[0])) 05: 06: void print_array(const int array[], size_t length); 07: 08: int main(void) 09: { 10: int array[10] = { 0 }; 11: 12: print_array(array, ARRAY_LENGTH(array)); 13: 14: for (int i = 0; i < ARRAY_LENGTH(array); ++i) { 15: array[i] = i * 10 + 1; 16: } 17: 18: print_array(array, ARRAY_LENGTH(array)); 19: 20: memset(array, 0, sizeof(array)); 21: 22: print_array(array, ARRAY_LENGTH(array)); 23: 24: return 0; 25: } 26: 27: void print_array(const int array[], size_t length) 28: { 29: for (int i = 0; i < length; ++i) { 30: printf("[%d]: %d\n", i, array[i]); 31: } 32: printf("\n"); 33: }次回はこのmemset()という関数について見ていきましょう。
注:この辺は私は専門家ではないので、厳密なところまで分かっているわけではないです。正確さを期すにはANSI Cの仕様書を参照するとか、複数のコンパイラの吐き出したアセンブラコードを比較検証してみるなどの作業が必要になるかと思います。 -
第199回 改めてCに挑戦!(18) 〜配列・4〜
この記事は、2011年10月31日に掲載されました。皆さんこんにちは、高橋真人です。
さて、前回ご紹介したプログラムでは、いろいろな配列の初期化の例をお見せしました。
まずは、単純なintの配列の例。const int int_array[] = { 0, 1, 2, 3, 4, 5, 6 };ポイントは、中カッコで囲み、カンマ区切りで羅列した要素が順に配列に格納されるというところ。配列int_arrayの要素数の指定を省略してあるため、コンパイラが初期化に使われる値の数(この例では7個)を数えて配列の長さを決定します。
constが付くと、この配列は変更されない(変更する意思がない)ことをコンパイラに伝えることになります。次に、文字列の配列の例。
const char *string_array[] = { "Hello", "world", "This is a pen." };この例は、文字列を「charへのポインタ」として表しています。初期化に使用されている3つの文字列は、文字列のデータ、つまり文字列を構成する各文字が配列の中に直接収まるのではなく、これらはメモリ上の別の場所に納められ、その場所を表すアドレス値が配列の要素として格納されます。
従って、この例を別の言い方で表現すると「ポインタの配列」となります。次も文字列の配列の例です。
const char string_array2[][15] = { "Hello", "world", "This is a pen." };今度の例も1つ前のものと極めて似ていますが、配列の宣言の部分がちょっとだけ異なります。前の例をポインタの配列というならば、こちらは「配列の配列」と言うことができます。
Cでは、多次元配列を作ることができないため、const char string_array2[][] = { "Hello", "world", "This is a pen." };と書くことはできません。(違いは、配列の要素数の2番目の「15」があるかないか、です)
つまり、上記のような二重構造になっている配列において、最初の配列の長さは省略して宣言することができますが、二番目の長さは省略できませんし、すべての長さは同じでなければなりません。
ですから、初期化に使用している3つの文字列の長さ(要素数。ヌル文字も含める)は6、6、15と異なっていますが、実際には3つの配列がすべて15という長さになってしまいます。この、「ポインタの配列」と「配列の配列」の違いは混乱する人も多いと思います。これをきちんと理解するためには、まず文字列を表すには配列を使う場合とポインタを使う場合があることを理解する必要があります。
以下のプログラムを走らせてみてください。01: #include <stdio.h> 02: 03: int main(void) 04: { 05: const char *s1 = "Hello world!"; 06: const char s2[] = "Hello world!"; 07: 08: printf("s1: %ld\n", sizeof(s1)); 09: printf("s2: %ld\n", sizeof(s2)); 10: 11: return 0; 12: }結果は以下のようになります。(32bit環境での実行結果です)
s1: 4 s2: 13s1が4になっているのは、s1はポインタなので32ビットで、つまり4バイト。それに対してs2は要素数13のcharの配列なので13バイトになるわけです。
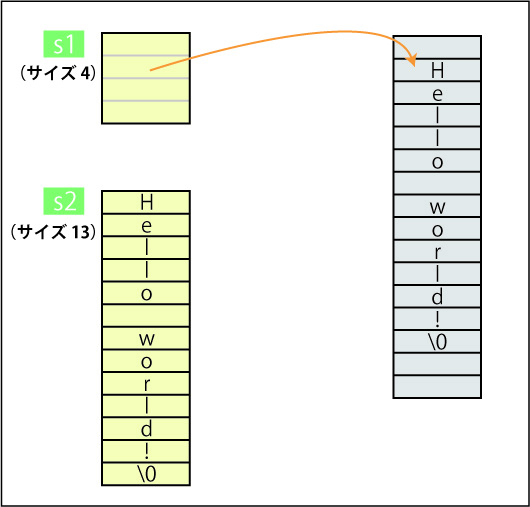
そして最後は構造体の配列です。
struct SomeStruct { int a; char s[100]; short b; }; const struct SomeStruct struct_array[] = { { 10, "Hello", 3 }, { 1000, "world", 72 }, { 100, "Bye", 83 } };初期化に使われる値が、二重構造になっていますが、外側の中カッコが配列、内側の中カッコは構造体のメンバに対応します。(順に、a, s, bに格納される)
ここでは構造体のメンバsはcharの配列ですから100バイトとなり、残りの要素のサイズである4(int変数のa)と2(short変数の2)を足して106になるかと思いきや、以前お話ししたアライメントの関係で、この構造体のサイズは108となり(32bit環境での場合)、配列全体のサイズは324バイトとなるわけです。 -
第198回 改めてCに挑戦!(17) 〜配列・3〜
この記事は、2011年10月22日に掲載されました。皆さんこんにちは、高橋真人です。
さて、2回ほど寄り道をして構造体について見てきましたが、これはその前からご説明している配列についてのお話の「事前準備」です。今回から配列に戻って、お話を続けていきます。
さて、配列のお話はコピーのところまで進んでいました。まず、配列同士では代入はできないこと、そしてそもそも配列全体に対しての代入はできないので、初期化の処理を除き、値の設定や他の配列からのコピーをするためには、各要素に1つずつ代入していかなければならないということをお話ししていました。
「続き」という意味では、「memmove()を使う場合と、memcpy()を使う場合の微妙な違いとは何か」ということをお話ししなければならないのですが、その前に「初期化」について触れておきたいと思います。以下は、配列を扱うプログラムの例ですが、特に初期化の部分について注意して見てみてください。
01: #include <stdio.h> 02: 03: #define ARRAY_LENGTH(ARRAY) (sizeof(ARRAY)/sizeof(ARRAY[0])) 04: 05: struct SomeStruct { 06: int a; 07: char s[100]; 08: short b; 09: }; 10: 11: void print_int_array(const int int_array[], size_t array_length); 12: void print_string_array(const char *string_array[], size_t array_length); 13: void print_string_array2(const char string_array[][15], 14: size_t array_length); 15: void print_struct_array(const struct SomeStruct struct_array[], 16: size_t array_length); 17: 18: int main(void) 19: { 20: const int int_array[] = { 0, 1, 2, 3, 4, 5, 6 }; 21: const char *string_array[] = { "Hello", "world", "This is a pen." }; 22: const char string_array2[][15] = { "Hello", "world", "This is a pen." }; 23: const struct SomeStruct struct_array[] = 24: { { 10, "Hello", 3 }, { 1000, "world", 72 }, { 100, "Bye", 83 } }; 25: 26: print_int_array(int_array, ARRAY_LENGTH(int_array)); 27: print_string_array(string_array, ARRAY_LENGTH(string_array)); 28: print_string_array2(string_array2, ARRAY_LENGTH(string_array2)); 29: print_struct_array(struct_array, ARRAY_LENGTH(struct_array)); 30: 31: return 0; 32: } 33: 34: void print_int_array(const int int_array[], size_t array_length) 35: { 36: printf("\n== %s ==\n", __FUNCTION__); 37: 38: for (int i = 0; i < array_length; ++i) { 39: printf("int_array[%d]: %d\n", i, int_array[i]); 40: } 41: } 42: 43: void print_string_array(const char *string_array[], size_t array_length) 44: { 45: printf("\n== %s ==\n", __FUNCTION__); 46: 47: for (int i = 0; i < array_length; ++i) { 48: printf("string_array[%d]: %s\n", i, string_array[i]); 49: } 50: } 51: 52: void print_string_array2(const char string_array[][15], size_t array_length) 53: { 54: printf("\n== %s ==\n", __FUNCTION__); 55: 56: for (int i = 0; i < array_length; ++i) { 57: printf("string_array[%d]: %s\n", i, string_array[i]); 58: } 59: } 60: 61: void print_struct_array(const struct SomeStruct struct_array[], 62: size_t array_length) 63: { 64: printf("\n== %s ==\n", __FUNCTION__); 65: 66: for (int i = 0; i < array_length; ++i) { 67: printf("struct_array[%d] - a: %d, s: %s, b: %d\n", 68: i, struct_array[i].a, struct_array[i].s, struct_array[i].b); 69: } 70: }少し長めのコードですが、やっているのは似たようなことの繰り返し。頑張って目を通してみてください。ちなみに、実行結果は以下の通り。
== print_int_array == int_array[0]: 0 int_array[1]: 1 int_array[2]: 2 int_array[3]: 3 int_array[4]: 4 int_array[5]: 5 int_array[6]: 6 == print_string_array == string_array[0]: Hello string_array[1]: world string_array[2]: This is a pen. == print_string_array2 == string_array[0]: Hello string_array[1]: world string_array[2]: This is a pen. == print_struct_array == struct_array[0] - a: 10, s: Hello, b: 3 struct_array[1] - a: 1000, s: world, b: 72 struct_array[2] - a: 100, s: Bye, b: 83本質的な解説は次回に回しますが、説明をいくつか。
冒頭で定義してある#defineから始まるマクロは、極めて常用されるパターンのマクロですが、配列の長さを得るためのものです。#define ARRAY_LENGTH(ARRAY) (sizeof(ARRAY)/sizeof(ARRAY[0]))例えばこれが、
ARRAY_LENGTH(int_array)という形で使われると(上記コードの23行目)、プリプロセッサによって以下のように展開されます。
sizeof(int_array)/sizeof(int_array[0])配列全体のサイズ(バイト数)を配列の先頭要素のサイズ(バイト数)で割ることによって、配列の要素数つまり長さが求められるという仕組みです。
それから、上記コードのstring_arrayとstring_array2ですが、これは両方とも「文字列の配列」ということになります。ですが、配列としては両者は異なります。以下のような簡単なプログラムを書いてみると、両者が違うことが分かります。01: #include <stdio.h> 02: 03: int main(void) 04: { 05: const char *string_array[] = { "Hello", "world", "This is a pen." }; 06: const char string_array2[][15] = { "Hello", "world", "This is a pen." }; 07: 08: printf("sizeof string_array: %ld\n", sizeof(string_array)); 09: printf("sizeof string_array2: %ld\n", sizeof(string_array2)); 10: 11: return 0; 12: }実行結果は、以下のようになります。
sizeof string_array: 12 sizeof string_array2: 45この配列は、それぞれ要素(文字列)の数が3つになっていますので、各要素の大きさは、string_arrayが4、string_array2が15ということになります。どうしてか分かりますか? 簡単なので次回まで考えてみてください。
-
第197回 改めてCに挑戦!(16) 〜構造体・2〜
この記事は、2011年09月30日に掲載されました。皆さんこんにちは、高橋真人です。
さて、前回の説明で構造体の基本が分かったところで(前回も申しました通り、今の段階では構造体の深い部分に触れるわけではありません)、以下のような構造体のケースについて考えてみたいと思います。struct Something { char c; short sh1; short sh2; long l; };まあ、この構造体が具体的にどういう用途に用いられるかは私も知りませんが(笑)、ここで問題です。この構造体のサイズはいくつでしょう?
さて、まず「サイズはいくつか?」という問いが発せられた場合、少なくともC言語の世界では多くの場合は「バイト数」を意味します。sizeofという演算子を憶えていますか? もし憶えていなければ、いま憶えましょう。この演算子は一項演算子(演算子の対象となるものが1つ)で、対象とできるものは変数や型です。
sizeof演算子の使い方を説明しがてら、上記の構造体を構成する各部品について大きさを調べてみましょう。sizeof(char) sizeof(short) sizeof(short) sizeof(long)このように、sizeofと書いた後にカッコで囲って対象となるものを書きますと、演算の結果としてそのバイト数が返ってきます。実際にプログラムにして走らせてみましょうか。
01: #include <stdio.h> 02: 03: struct Something { 04: char c; 05: short sh1; 06: short sh2; 07: long l; 08: }; 09: 10: int main(void) 11: { 12: printf("sizeof(Struct Something): %ld\n", sizeof(struct Something)); 13: 14: printf("sizeof(char): %ld\n", sizeof(char)); 15: printf("sizeof(short): %ld\n", sizeof(short)); 16: printf("sizeof(short): %ld\n", sizeof(short)); 17: printf("sizeof(long): %ld\n", sizeof(long)); 18: 19: return 0; 20: }さて、このプログラムを走らせてみた結果が以下です。(64bit環境で走らせると、結果には多少の違いが出ます。以下のプログラムでも同様)
[Session started at ... sizeof(Struct Something): 12 sizeof(char): 1 sizeof(short): 2 sizeof(short): 2 sizeof(long): 4 The Debugger has exited with status 0.注目してほしいのは、構造体をまとめてサイズを調べた場合と、構造体を構成する各要素と同じもののサイズを個別に比べた場合で違いが出ていることです。
一体どうしたのでしょう? もしかして、構造体を作るとその構造体の管理のために特殊な領域が使われてしまうとか?その答えをお伝えする前に、今度は別の構造体で試してみましょう。
01: #include <stdio.h> 02: 03: struct Something { 04: char c[2]; 05: short sh; 06: short sh[2]; 07: long l; 08: }; 09: 10: int main(void) 11: { 12: printf("sizeof(Struct Something): %ld\n", sizeof(struct Something)); 13: 14: printf("sizeof(char[2]): %ld\n", sizeof(char[2])); 15: printf("sizeof(short): %ld\n", sizeof(short)); 16: printf("sizeof(short[2]): %ld\n", sizeof(short[2])); 17: printf("sizeof(long): %ld\n", sizeof(long)); 18: 19: return 0; 20: }わずかですが、要素を変えてみました。さて、これを走らせるとどうなるでしょうか?
[Session started at ... sizeof(Struct Something): 12 sizeof(char[2]): 2 sizeof(short): 2 sizeof(short[2]): 4 sizeof(long): 4 The Debugger has exited with status 0.こんどは、両方とも同じサイズになりましたね。つまり、先ほどの仮説「構造体を管理する領域として何バイトかが使われているのでは?」というのはどうも違うようです。
何故、このようになるのかを説明するために、今度は次のようなプログラムを試してみてください。
01: #include <stdio.h> 02: 03: struct Something { 04: char c; 05: short sh1; 06: short sh2; 07: long l; 08: }; 09: 10: int main(void) 11: { 12: struct Something something; 13: printf("start of struct: %p\n", &something); 14: printf("start of c: %p\n", &something.c); 15: printf("start of sh1: %p\n", &something.sh1); 16: printf("start of sh2: %p\n", &something.sh2); 17: printf("start of l: %p\n", &something.l); 18: 19: return 0; 20: }結果は以下のようになります。
[Session started at ... start of struct: 0xbffff684 start of c: 0xbffff684 start of sh1: 0xbffff686 start of sh2: 0xbffff688 start of l: 0xbffff68c The Debugger has exited with status 0.このプログラムが何をやっているのかというと、struct Something型の構造体の変数を1つ定義し、これがメモリ上にどう配置されているのかを調べているのです。
構造体自体の先頭と、第一要素のcの位置が同じ場所にあることが分かりますね。そして、1バイトのcの次の要素であるsh1がcの位置から1バイト後にあるのではなく2バイト後にあるのが分かります。また、3番目の要素のsh2は2バイトなのに、4番目の要素のlの位置は、sh2の2バイト後にあるのではなく4バイト後にあります。実は、構造体がメモリ上に作成される際、各要素は隙間なくビッチリ詰められるのではなくて、それぞれの要素のサイズに応じて「偶数バイト目」とか「4の倍数バイト目」に配置されるのです。そのため、構造体の構成要素の組み合わせによっては、今回のように「隙間」ができることがあるのです。
何故、このようになるかというと、私も余り詳しいことは分かりませんが、CPUがメモリにアクセスする際にその方が効率よく行うことができるからだそうです。
詳しく知りたい方は、「アライメント」とか「パディング」などという言葉で調べてみるとより深い情報が得られるかもしれません。 -
第196回 改めてCに挑戦!(15) 〜構造体・1〜
この記事は、2011年09月27日に掲載されました。皆さんこんにちは、高橋真人です。
さて、いきなりの構造体です(笑)。配列の説明はまだまだ続きますが、先を説明する関係上、ここでちょっと構造体に寄り道します。
とはいえ、あくまで配列の説明上必要な構造体の話をするわけなので、構造体の基本的な部分はさらっと触れるにとどめ、本格的な解説に関してはまた機会を改めて、ということになりますのでお間違えなきよう。構造体というのは、C言語における唯一とも言える「ユーザーが独自に定義可能な」型です。構造体を使うことで複数の情報を1つにまとめて扱うことができるようになります。
私もCの学習者のころに感じたことがありますが、時々「なぜ、わざわざ構造体を作る必要があるの?」という疑問を持つ方が必ずいらっしゃいます。確かに、構造体という形にわざわざまとめておかなくても(何しろ、基本的には構造体を使うためにはまず自分で構造体を設計しなくてはなりませんから)複数の変数を用意すればいいんじゃないかと思うのです。
例えば、構造体の説明によく使われる人の情報を収めるケースで考えてみましょう。
まず、構造体を作るとしたら、例えば以下のようにできるでしょう。struct Person { char first_name[100]; char last_name[100]; short age; };Personという「タグ」を付け、姓、名、年齢を並べただけの単純な情報です。では、今度はこれを構造体を使わずに表現してみます。
char person_first_name[100]; char person_last_name[100]; short person_age;変数名が少し長くなってしまったものの、何の問題もなく定義できます。
「だったら、それでいいんじゃないの?」と思われるかもしれませんね。確かにそれでもいいんです(笑)。
ただ、それでもあえて構造体を使うのはひとえに「便利だから」です。人の情報を扱うプログラムの場合、ほぼ例外なく「複数の人の情報」を扱いますよね、複数の情報を扱うならば当然配列を作ります。あ、もちろん配列を使わずに、struct Person person1; struct Person person2; struct Person person3; struct Person person4; ...とやっても悪いことはないんですが、このように変数名の中に順番の情報を入れてしまうと、ループなどを使って順番に処理していくのが面倒というか実質的には不可能になってしまうので、まずやりません。
で、配列を作るとして、構造体ですと、以下のような感じになります。
struct Person person[20];これで、姓、名、年齢の情報が一挙に20人分用意できるのでラクですね。あ、まあそれは置いときましょうか。では、構造体を使わないケース、
char person_first_name[20][100]; char person_last_name[20][100]; short person_age[20];こんな感じになります。見た目がごちゃごちゃしてるのは、まあ承知の上なので無視するとしましょう。では、実際に情報を収めてみることにします。データを用意するのが面倒なので、人数は5人分にしてしまいますね(笑)。
まずは、構造体を使ったケース。
01: #include <stdio.h> 02: 03: struct Person { 04: char first_name[100]; 05: char last_name[100]; 06: short age; 07: }; 08: 09: void print_person_info(struct Person person); 10: 11: int main(void) 12: { 13: struct Person person[5] = { 14: { "John", "Doe", 20 }, 15: { "Jane", "Clerk", 18 }, 16: { "Mary", "Johnson", 32 }, 17: { "Tom", "Jones", 40 }, 18: { "Michael", "Kay", 27 }, 19: }; 20: 21: // print persons information 22: for (int i = 0; i < 5; ++i) { 23: print_person_info(person[i]); 24: } 25: 26: return 0; 27: } 28: 29: 30: void print_person_info(struct Person person) 31: { 32: printf("Last name: %s, First name: %s, age: %d\n", person.last_name, person.first_name, person.age); 33: }次に、構造体を使わないで書いてみたケースです。
01: #include <stdio.h> 02: 03: void print_person_info(char last_name[], char first_name[], short age); 04: 05: int main(void) 06: { 07: char person_last_name[][100] = { "Doe", "Clark", "Johnson", "Jones", "Kay" }; 08: char person_first_name[][100] = { "John", "Jane", "Hary", "Tom", "Michael" }; 09: short person_age[] = { 20, 18, 32, 40, 27 }; 10: 11: for (int i = 0; i < 5; ++i) { 12: print_person_info(person_last_name[i], person_first_name[i], person_age[i]); 13: } 14: 15: return 0; 16: } 17: 18: 19: void print_person_info(char last_name[], char first_name[], short age) 20: { 21: printf("Last name: %s, First name: %s, age: %d\n", last_name, first_name, age); 22: }いかがでしょうか?
たとえば、関数にだれか一人の情報を渡すなどと言った場合、構造体を使うと受け渡しがラクにできますが、構造体を使わないと要素を1つずつ全部引数に渡さなければなりません。
今回の例ではまだ姓と名と年齢の3つだけなのでいいですが、これに住所だとか電話番号だとか勤務先の情報とかまで加わってきた場合には、さらにprint_person_info(person_last_name[i], person_last_name[i], person_age[i], person_address[i], person_phone_number[i], person_office[i]);なんて具合になってきます(笑)。
さて、今回は、普通だったら「構造体を使うと情報をまとめて扱えるので便利です。皆さんも荷物を持ち歩く時にバラバラのままで運ぶよりも箱に入れたりバッグに入れて運ぶでしょ?」と言えば済むところをあえて実例を示して解説してみました(笑)。
ここまでやってる例はあまり見ないと思いますが、これで「何で構造体なんて必要なの?」と思っている人にも納得していただけたのではないかと思います。それでもまだ納得できない方は、MOSAのBBSにでも質問をしてみてください(笑)。
ところで、今回の例では、関数に構造体を渡す際に「そのまま」つまり値渡しをしました。これは、まだ構造体とポインタの関係をきちんと説明していなかったのでそうしたのですが、通常は構造体を関数に渡す場合にはポインタを使うということを憶えておいてください。
これは、見た目の問題だけではく、実際に受け渡されるデータの量が格段に少なくて済むので、処理速度(パフォーマンス)的にも効率が良いのです。この辺はいずれまた別の機会に触れようと思います。 -
第195回 改めてCに挑戦!(14) 〜配列・2〜
この記事は、2011年08月31日に掲載されました。皆さんこんにちは、高橋真人です。
前回、「配列から配列への代入はできない」ということを申しました。繰り返しになりますが、「配列はCでは型ではない」ので、Cの機能として配列の代入をするものはありません。
ですが、Cの標準ライブラリであるANSI Cライブラリにはちゃんと配列同士で代入(もちろん、厳密には配列そのものの代入ではない)を行うための機能は備わっています。その機能の話をする前に、ちょっと勘違いをしている方もおいでかもしれないので1つだけ触れておきたいことがあります。前回触れた「配列を右辺値として使う場合」の話です。以下のコードを見てください。
01: #include <stdio.h> 02: 03: int main(void) 04: { 05: int array1[] = { 1, 2, 3, 4, 5 }; 06: int *array2; 07: 08: array2 = array1; 09: 10: for (int i = 0; i < 5; ++i) { 11: array2[i] = array2[i] * 2; 12: } 13: 14: for (int i = 0; i < 5; ++i) { 15: printf("array[%d]: %d\n", i, array2[i]); 16: } 17: 18: return 0; 19: }前回のものを、ほんのわずか変更しただけのコードですが、今度はちゃんとコンパイルもでき、動作もします。
8行目では、一見、配列が代入されているかのように見えます。
ですが、6行目の変数の定義部分を見れば分かるように、array2は配列ではなくポインタです。ただ、注意していただきたいのは- ポインタに配列が代入されているわけではない
ということです。そもそも、Cの大原則として「型の違うもの同士を代入することはできない」ですから、ポインタに配列を代入することはできませんし、そもそも配列は何かに代入することもできないのです。
よって、ここのコードで何が行われているかといえば、- 配列array1の先頭要素を指すポインタ(もしくは先頭要素のアドレス値)がポインタ変数であるarray2に代入されている
のです。(前回説明した通り)
ですから、08: array2 = array1;の部分は、
08: array2 = &array1[0];と書き換えても全く同じことになります。
ここで大切なポイントは前回も触れましたが、- 配列は右辺値として使われるとき、先頭要素のポインタに変換される
ということです。
ここをきちんと理解し、このようなケースで常に「あ、これはそういうことだな」と分かるようになると、配列の扱いがスムーズにできるようになりますので、ぜひきちんと理解してください。ところで、配列を配列に代入する(やり方はあとで説明します)のと、先頭要素のポインタをポインタに代入するのとでは何が違うのか、分かりますか? 一見、両者は同じように動作するように見えます。しかしながら、ポインタを代入した場合、配列そのものは一つしか存在しません。
対して、配列の代入を行った場合には配列は複製されて2つになるのです。今までも何度か触れてきていますが、Cで言う「値渡し」すなわち代入は、値をコピーすることを意味します。渡したからと言って、元の値がなくなってしまうわけではなく、元の値は何ら変更されることなく「そのまま残り」ます。
分かっていればどうってことのない話ですが、ついつい「渡す」という表現から意味を取り違えてしまうと混乱することになりますから、注意しましょう。さて、今回の本題とまいりましょう。
ANSI Cのライブラリに備わっている「配列同士を代入する」機能は2つあります。void *memcpy(void *to, const void *from, size_t data_size); void *memmove(void *to, const void *from, size_t data_size);の2つです。
使い方はどちらも同じです。今までのコードをmemcpy()を使って置き換えると、次のようになります。01: #include <stdio.h> 02: #include <string.h> 03: 04: int main(void) 05: { 06: int array1[] = { 1, 2, 3, 4, 5 }; 07: int array2[5]; 08: 09: memcpy(array2, array1, sizeof(array1)); 10: 11: for (int i = 0; i < 5; ++i) { 12: array2[i] = array2[i] * 2; 13: } 14: 15: for (int i = 0; i < 5; ++i) { 16: printf("array[%d]: %d\n", i, array2[i]); 17: } 18: 19: return 0; 20: }memmove()を使う場合も、基本的には同じです。ただ、もちろん両者にはちょっとした違いがあります。次回はその辺も含めてお話ししていきます。
-
第194回 改めてCに挑戦!(13) 〜配列・1〜
この記事は、2011年08月25日に掲載されました。皆さんこんにちは、高橋真人です。
関数とその引数にポインタを渡すケースに関してはある程度説明し尽くしましたので、この辺でテーマを配列に向けてみたいと思います。配列は、Cではとても頻繁に使われるデータ構造です。ですが、配列はCでは「型ではありません」。
「え、型ではない?!」と驚かれる方もおいでかもしれません。まあ、考え方によっては「配列は型である」という立場を取る方もおいでかもしれませんが、とりあえずこの連載では「配列は型ではない」というスタンスを取ります。別に「規格として厳密にどうこう」ということを言いたいわけではなく、「配列は型でないのだ」と考えることによりCに対する理解がより深まると思うからこのように説明をするのです。では、配列が型ではないということはどういうことかというと、
- 配列同士では代入ができない
この1点に表されています。初心者の方がよくやりがちなミスに以下のようなコードがあります。
01: #include <stdio.h> 02: 03: int main(void) 04: { 05: int array1[] = { 1, 2, 3, 4, 5 }; 06: int array2[5]; 07: 08: array2 = array1; 09: 10: for (int i = 0; i < 5; ++i) { 11: array2[i] = array2[i] * 2; 12: } 13: 14: for (int i = 0; i < 5; ++i) { 15: printf("array[%d]: %d\n", i, array2[i]); 16: } 17: 18: return 0; 19: }実際に打ち込んで試してみた方はお分かりでしょうが、このコードは実はコンパイルできません。8行目のところで、「error: incompatible types in assignment」というエラーが出てしまいます。
このエラーの意味は、「互換性のない型同士を代入しようとしています」ということになりますが、ここで「型」という表現に過剰反応しないでください(笑)。あくまで、代入をできるための互換性がないですよ、ということを表しているにすぎません。
あと、本題には関係ないですが上のコードで気になる点がある方もおいでかもしれないので簡単に説明しておきますが、5行目の書き方、これは配列のサイズをコンパイラに決めさせる、つまり初期化時に与えた値を使って配列の大きさも決めてしまうという書き方です。
通常の配列の定義では、int array[10];のように書きます。で、定義と同時に初期化もする場合には、
int array[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };のように書きます。配列のサイズ「10」に対して、初期化値として10個の整数値が割り当てられるのです。ただし、配列のサイズと初期化する値の数が一致しないケースもあり得ます。例えば、
int array[10] = { 1, 2, 3 };というように書いた場合、配列のサイズは10個あるのに対して、初期化する値の数は3つしかないわけです。この場合、残りの7個は0に初期化されます。つまり、「初期化の値が割り当てられない配列の要素は0に初期化される」ことになっています。
ただし、単にint array[10];と書いた場合は10個の要素が0に初期化されるのではなく、「配列の要素は初期化されていない」という意味になるので注意しましょう。もし、すべての要素を0に初期化したい場合には、
int array[10] = { 0 };と書けばいいのです。
ちなみに、上の例とは逆に、指定の数よりも初期化値の数の方が多かった場合には、あくまで「指定した配列のサイズが優先」されます。つまり、int array[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 };とした場合、配列のサイズは10になり、初期化の値は先頭から10個分だけが利用されて、残りの値は無効となります。(古い規格では「エラー」になるようです)
さて、話を本題に戻しましょう。
先のコード例で、エラーになる8行目は「配列に配列を代入しようとしている」ことになります。まず、Cの原則として「配列への代入はできない」という規則があります。ただ、興味深いことにここで行われようとしていることは「配列に配列を代入しようとしている」わけではないのです。って、言ってることが矛盾してますね(笑)。
まあ、コード例を書いた意図は「配列に配列を代入しようとした」のですが、実際にはそうなっていないのだ、というふうに理解してください。
では、どうなっているのかと言いますと、ここが配列の少し厄介なところで、配列の名前を右辺値(憶えてますか? 忘れた方は連載の第192回を参照してください)として書いた場合、それは「先頭の要素を指すポインタとして解釈される」のです。
つまり、array1 = array2;は、
array1 = &array2[0];と等しいということです。
しかしながら、配列の名前を左辺値に書いた場合にはそうなりません。というか、配列は左辺値に置くことができないのです。つまり、- 配列のすべての要素にいっぺんに値を設定できるのは初期化のときだけ
ということになります。これ、とても大事! しっかりと憶えておきましょう!
-
第193回 改めてCに挑戦!(12) 〜関数・8〜
この記事は、2011年07月29日に掲載されました。皆さんこんにちは、高橋真人です。
ポインタは「何かを指す」ものだと言われます。そのためポインタ自体が何か特別なもののようにとらえられ、さらに実体がつかみにくいような印象を与えられることで、学習者にとって「曖昧なもの」のように受け止められることがあるようです。
最近の連載で扱っている「関数の引数でのポインタの利用」に関しても、この辺の事情が学習者の「理解のしにくさ」を招いているような気もします。また、Cを使う人の間ではよく、関数の引数にポインタを使用した場合に「参照渡し」という言い方をすることがあります。しかしながら、この連載でもさんざん繰り返してきていますように、厳密に言えば「Cには参照渡しはない」(つまり、すべてが値渡し)のです。それでも、ポインタの扱いに慣れてくるとむしろこの表現の方がピンと来ることがあるのです。
私たちの実生活でも、現実にはあり得ないことを表現として使うことはありますよね。例えば、急いで相手のところに行くことを表すのに「今すぐ飛んで行きます」などと言っても、実際に空を飛ぶわけでもないし、飛行機を使うわけでもない。それでも、その表現には「できるだけ速く行こうとしているのだ」という発言者の「意図」が込められているわけです。
同じように「参照渡し」という表現にも、「ここで肝心なのはポインタの値なのではなく、それが表しているモノの方なのだ」という「意図」が込められています。
だから、いくら私が「Cには値渡ししかない」と強調したからと言っても、それはあくまで理屈の話であって、日常的にプログラマが会話する時に「参照渡し」という表現を使ったからと言っても、それが「間違っている」ということになるわけでもないのです。(むしろその方がコミュニケーションがスムーズに行ったりする)
皆さんもこの辺の「さじ加減」が分かり、厳密には間違った表現であったとしても「参照渡し」という言葉を使いこなせるようになれば、Cプログラマとしても一段上に上がったと言えるかもしれません(笑)。ですが、その意味するところが何であるのか、厳密には何が起こっているのかをしっかりと理解しておかなければ、単に「言葉に振り回されているだけ」に終わってしまいますのでくれぐれも注意してくださいね。さて、ポインタが関数に引数として渡されるとき、その値はコピーして渡され関数の処理が終わると同時に捨てられます。ですが、渡した情報が関数の中で利用されることで、その関数の中から「関数の外部にある」何か(変数など)が操作されることになるのです。
この辺をちょっとしたたとえ話で説明してみましょう。
何とも突拍子のない例で恐縮ですが、いま私が巨大なロボットを作っているとします。作業を進めて行く中で、左右の腕のパーツを逆に付けてしまっていたことに気付いたのです。付いていない状態から取り付けを行うのは素人の私にも簡単なのですが、一度付けてしまうとその構造上、取り外すには専門業者の技術と特殊な工具が必要です。仕方ないので、私もとある業者に作業を頼むことにしました。
作業を依頼するために私は業者のもとに出向いていったわけですが、当然ロボット自体は大きいし重いし、とてもその業者のところに運んで行けるようなしろものではないので、出張修理を依頼することになりました。そこで業者の元にメモ書きを残してきました。そこにはロボットが置いてある倉庫の住所が書いてあるのです。「この住所にある倉庫にロボットが置いてあるので、左右のパーツを付け替えて正常に戻してください」と。
数日後、私は業者から「作業が終了しました」と連絡をもらい、倉庫に行ってみると無事に左右のパーツは正常に取り付け直されていたのでした。
とまあ、こんな他愛のないたとえ話ですが、この話の例を元に「関数にポインタを渡すこと」を考えてみます。
まず、業者は関数に該当します。そして、業者の元に残してきたメモ書きがポインタに当たります。実際に操作対象になるモノ(ここではロボット)自体は直接関数(業者)に渡されるのではなくて、単に「どこにそれがあるのか」の情報だけが「値として」渡されるわけです。業者は私から指示された作業を完了してしまった後にはそのメモ書きを捨ててしまって構わないのです。あくまで作業を行うに際して「操作の対象物がどこにあるのか」の情報をそのメモ書き(関数に置けるポインタ引数)から読み取れば、それで目的は達成されるからです。
さて、かなり突飛な例でご説明してみましたが、ポインタというもののイメージが皆さんの中で少しはクッキリしたものになりましたでしょうか? 特に、「ポインタの引数も、値自体はコピーして渡されて捨てられる」という辺りについてご理解いただければ幸いです。











